On January 29, 2025, barely within a couple of weeks after DeepSeek made waves all across the world, Alibaba Cloud released Qwen2.5-Max as their latest advanced artificial intelligence chatbot. The new multimodal LLM chatbot poses challenges to not only the leading players like GPT-4, LLaMa, and Claude but even the latest formidable challenger DeepSeek.
Alibaba’s Qwen2.5-Max model introduces significant enhancements, including advanced coding proficiency, extended context handling of up to 128,000 tokens, improved instruction adherence, and multilingual support for over 29 languages. Specialized variants like Qwen2.5-Coder and Qwen2.5-Math further extend its capabilities in coding and mathematical reasoning.
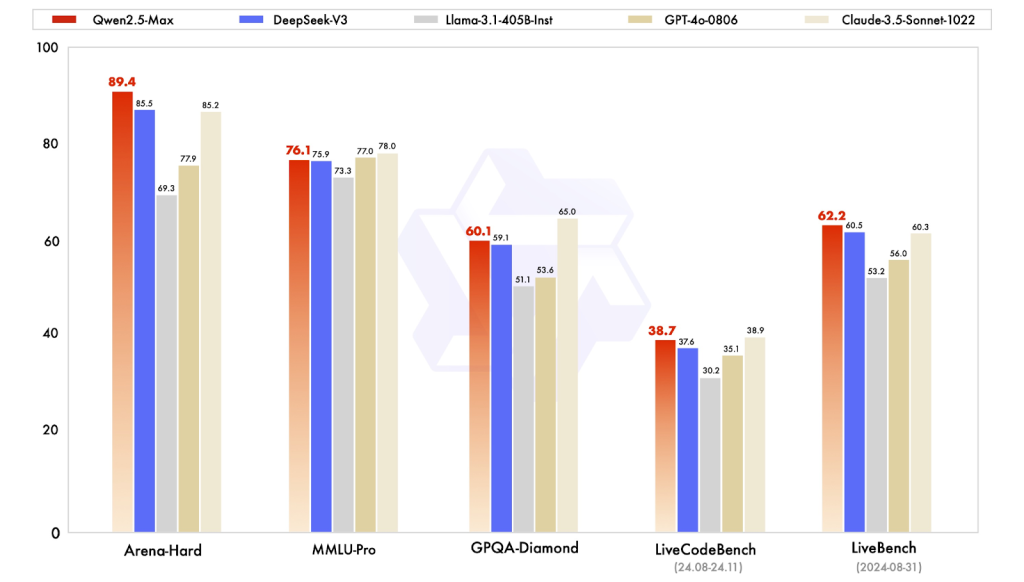
Fig. 1: Qwen2.5-Max comparison with its competitors (Reference: Qwenlm)
Where Does Qwen2.5-Max Shine?
Qwen2.5-Max outperforms leading models, including the latest DeepSeek V3 and OpenAI’s GPT-4o, across key benchmarks such as Arena-Hard, LiveBench, and GPQA-Diamond, demonstrating superior performance in knowledge assessment, coding capabilities, and general tasks. Here’s a comparative table showcasing how different models perform on each of the benchmarks.
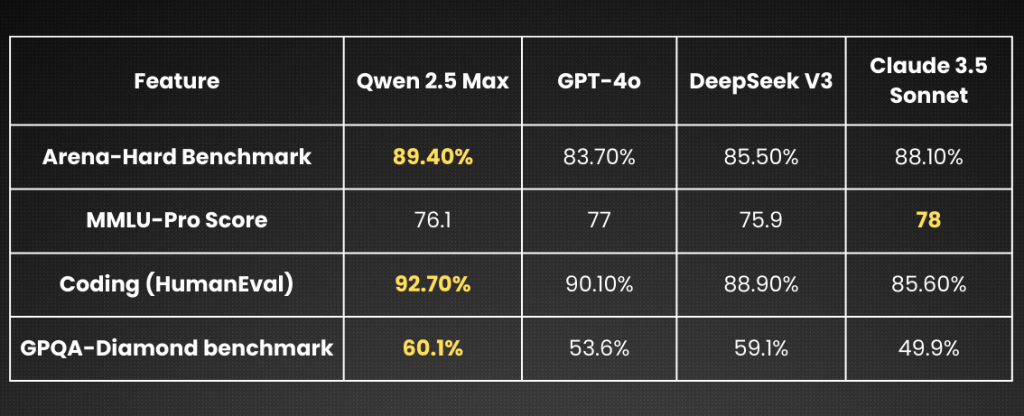
Fig. 2: Benchmark Performance Comparison of Leading LLMs
Unmatched Features at a Glance
- Mixture-of-Experts (MoE) Architecture: Activates specialized submodels for specific tasks, enhancing efficiency and performance.
- Extensive Training: Pretrained on over 20 trillion tokens, ensuring a comprehensive understanding across diverse domains.
- Advanced Fine-Tuning: Refined through Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) for optimal task performance.
We will discuss in detail about all these advanced and innovative ideas later in the blog that enable Qwen to surpass leading LLMs on multiple fronts.
But before that let’s explore where Qwen2.5-max shines:
1. Logical and Methodical
Alibaba Cloud’s Qwen2.5-Max demonstrates exceptional logical reasoning capabilities, as evident by its performance on the Arena-Hard benchmark. This benchmark assesses an AI model’s ability to handle complex, multi-step logical reasoning tasks. Qwen2.5-Max achieved a score of 89.4%, surpassing other leading models such as GPT-4o, which scored 83.7%, and Claude 3.5 Sonnet, which scored 88.1%. Even the refined DeeSeek’s score for this model was lagging at 85.50%.
2. Better at Coding
Detailed benchmark comparisons among Qwen 2.5 Max, DeepSeek V3 R1, ChatGPT (GPT-4), and Kimi k1.5 have tested their respective coding capabilities across different global benchmarks. The analysis focused different indicators like accuracy of generated code, support for multiple programming languages, error handling capabilities, code optimization, and complex problem solving capabilities. Let’s check in detail how each of these models compare:
Code Generation Accuracy:
Qwen 2.5 Max consistently excelled at generating syntactic code that was not only correct but also functionally accurate. The HumanEval pass rates for Qwen2.5-Max were between 87% and over 90% depending on the variant. In contrast, DeepSeek V3 R1 typically achieves around a 79% pass rate. ChatGPT and Kimi k1.5, on the other hand, deliver competitive performance in straightforward and simpler tasks, but sometimes struggle with intricate logic and edge cases. It means that Qwen 2.5-Max came out as the frontrunner in complex code generation scenarios. Similarly, on the LiveCodeBench benchmark, which evaluates a model’s ability to generate and execute functional code, Qwen2.5-Max achieved a score of 38.7, narrowly surpassing DeepSeek-V3’s 37.6.
Multilingual Support
Qwen2.5-Max is also leading in its support for multiple programming languages by demonstrating proficiency in Python, JavaScript, Java, C++, and even some less common frameworks. It’s not only the support for the syntax ans semantics – but also cleverly using the libraries and tools that help Qwen to deliver high-quality outputs across the board. While DeepSeek V3 R1 and Kimi k1.5 also support a wide range of languages, but they do show inconsistencies in some platform or domain specific languages like Rust or Kotlin. Finally, ChatGPT does offer strong multilingual capabilities but it too lacks sometimes when it comes to refined optimizations that were present in Qwen’s outputs.
Error Handling and Debugging
One of the most critical aspect of coding is error detection and resolution – and most coding assistant are being developed for the sole purpose of improving this metric. Qwen 2.5 Max stands out, once again, by identifying subtle bugs and providing actionable fixes with a debugging effectiveness around 92%. Depending on the codebase and parameter tuning, DeepSeek V3 R1 and ChatGPT typically achieve effective debugging rates in the range of 84% to 88%. On the other hand, Kimi k1.5 did make useful suggestions, but sometimes require additional refinement for complex logical scenarios.
Code Optimization
We all are aware the need for optimized code for performance-critical applications. On this count too, Qwen 2.5-Max delivers cleaner, faster, and more efficient output balancing readability with runtime performance–reducing the need for manual adjustments. In comparison, while ChatGPT and DeepSeek V3 R1 generate functionally correct code, but lag in efficiency many times. Kimi k1.5, on the other hand, produces outputs that may often require further tuning to fulfill optimization needs.
Complex Problem Solving
Algorithm design and data structure implementation are considered to be fairly complex challenges and require superior multistage reasoning. On this parameter too, Qwen 2.5-Max outshines the rest, as a testimony to its advanced analytical capabilities, by solving close to 89% of problems correctly. DeepSeek V3 R1 manages around 76%, while ChatGPT and Kimi k1.5 often struggle with the depth needed for the more intricate tasks.
To conclude, as far as the coding prowess is concerned, while ChatGPT, DeepSeek V3 R1, and Kimi k1.5 can each bring a lot to the table (or the coder’s screens), many comprehensive and competitive benchmarks show that Qwen 2.5-Max consistently leads in critical areas. Be it code generation accuracy, robust multi-language support, error handling, optimization of code, and advanced complex problem-solving capabilities, Qwen2.5-max tops the charts to become the assistant of choice developers.
3. More ‘Common’ Sense
The GPQA-Diamond benchmark is designed to test AI models on challenging questions that require deep reasoning, knowledge retrieval, and problem-solving skills. These questions span a wide range of topics, many STEM disciplines including physics, mathematics, biology, and even general knowledge, making it one of the most rigorous evaluations of STEM and common-sense reasoning. It challenges models with graduate-level questions in these requiring deeper reasoning and precise knowledge retrieval.
In recent evaluations Qwen 2.5-Max achieved a score of 60.1 on the GPQA-Diamond benchmark, slightly surpassing DeepSeek-V3’s score of 59.1, indicating that Qwen 2.5-Max has an edge in applying and processing complex, multistage reasoning for answering challenging queries. Some evaluations reported that Claude 3.5 Sonnet can achieve even higher scores (up to 65.0), underscoring that the domain is still open for any one model to be declared a clear winner.
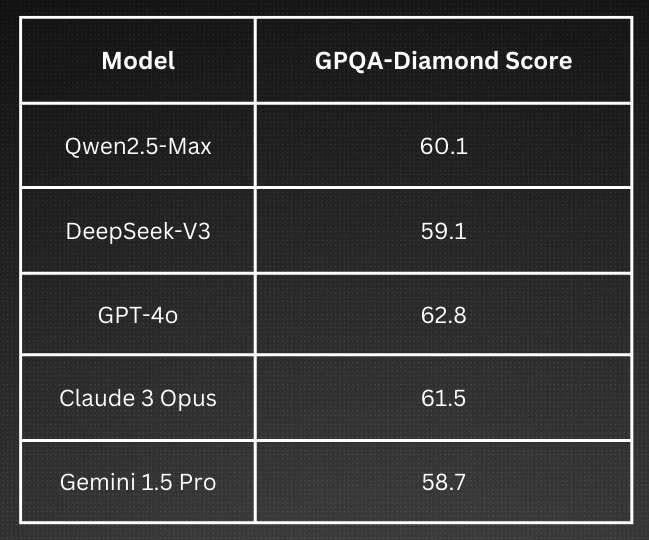
Fig. 3: The (not so) superior performance of Qwen2.5-Max
This only goes on to show that while no single model dominates all aspects of reasoning and knowledge retrieval, Qwen2.5-Max offers a worth-noticing mix of accuracy, depth, and practical utility.
4. Economical on Budgets
It is also economical to use Qwen 2.5-Max, not only by individuals but also by enterprise clients, thanks to its competitive pricing. As per the latest listed prices, Alibaba Cloud offers plans for Qwen 2.5-Max starting at just $0.38 per million input tokens. By comparison, pricing for similar models is considerably higher. More details on pricing and availability are shared later in the blog.
While DeepSeek is an open-source and nearly free alternative, it remains a blind spot for many enterprises. Despite its affordability, concerns around ecosystem maturity, security and privacy, enterprise-grade support, and integration capabilities make it less viable for businesses that prioritize reliability and seamless deployment. In contrast, Qwen2.5-Max balances affordability with strong cloud support, making it a more attractive option for cost-conscious yet performance-driven users.
Architecture and Training Methodology
This breakthrough model from Alibaba leverages a Mixture-of-Experts (MoE) architecture and extensive pre-training on over 20 trillion tokens to achieve advanced language understanding and generation capabilities. Not only the architecture but the training methodology also incorporates innovations like large-scale distributed computing, data preprocessing & augmentation techniques, and post-training fine-tuning for specialized tasks to enhance performance across multiple benchmarks.
Let’s see how the Qwen2.5-Max was designed, built, and trained to achieve path-setting outcomes.
Architectural Innovation
Qwen2.5-Max is built on a highly efficient and scalable architecture combining a Mixture-of-Experts (MoE) design with a transformer-based framework (incidentally most successful and popular LLMs are transformer-based). This hybrid structure enables optimized computational efficiency, reduced memory usage, and enhanced contextual understanding, making it well-suited for complex language processing tasks.
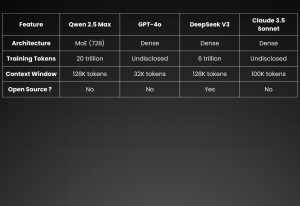
Fig. 4: An architectural comparison of leading LLMs
1. Mixture-of-Experts (MoE) Model
Qwen2.5-Max includes the Mixture-of-Experts (MoE) architecture as one of its central design elements.
This system contains 72 billion distributed parameters which are organized into 64 individual experts as part of its design structure. Only specific groups of expert components become active to process input data during inference since this method generates optimized computational resource utilization.
The selective expert activation process allows Qwen2.5-Max to reduce its memory requirements and computation by approximately 30% which results in faster response times while maintaining the same level of accuracy at a fraction of the cost of a traditional approach.
2. Transformer-Based Framework
Self-Attention Mechanism in Qwen2.5-Max applies layers that allocate weight values to words based on their relation to other words to obtain precise contextual interpretations.
The model utilizes Layer Normalization combined with Residual Connections as stabilization mechanisms which enhance training stability while improving learning speed during training from extensive datasets.
Training Innovation
1. Data Collection and Preprocessing
The Qwen2.5-Max model serves as a vast Mixture-of-Experts (MoE) system built to reach sophisticated language understanding and handle multiple inputs. It was pre-trained with more than 20 trillion tokens from a wide range of textual sources that encompass academic papers, web pages, books, and multimedia documents.
Qwen2.5-Max benefits from data augmentation through back-translation and synonym replacement as it improves language interpretation and reduces input variation sensitivity. The training samples become more diverse because of these methods, which allow the model to understand effectively multiple linguistic variations. The clever use of expert networks (MoE architecture) that specialize in different language processing tasks along with a gating network operates as an analysis system that selects appropriate expert networks for each request to achieve efficient and scalable processing.
Qwen2.5-Max provides a large context window extending to 131,072 tokens, enabling effective processing and generation of long-form content. The model outperforms DeepSeek V3, GPT-4o, and Claude 3.5-Sonnet on multiple benchmarks, as shown by performance results shared above.
2. Training Process
The distributed training protocol of Qwen2.5-Max employs many GPUs throughout its high-performance cloud platform. The system uses tensor and pipeline parallelism methods to process large datasets effectively. The model receives trillions of tokens for pre-training before it receives supervised learning with labeled datasets for fine-tuning tasks such as code generation, logical reasoning, and multilingual processing to boost real-world application performance.
The Qwen2.5-72B model requires two A100 GPUs to operate and needs 144.69 GB of GPU memory in BF16 precision. The GPU memory requirement for Int8 quantized Qwen2.5-72B amounts to 81.27 GB when deployed on dual GPUs. Multiple high-memory GPUs are required for the model to operate at its best according to these configurations.
Pricing and Availability
Interestingly, the Qwen2.5-Max system provides developers with an OpenAI API design duplicate, enabling easy migration from OpenAI platforms to Qwen2.5-Max. The design of Qwen2.5-Max enables users to add it effortlessly to their current systems. Qwen2.5-Max reaches users through Alibaba Cloud’s services and presents interfaces that accommodate different skill levels among users.
Qwen2.5-Max provides customers with a cost-efficient solution that outperforms other dominant AI models in the market. For example, GPT-4o’s pricing starts at $5.00 per million input tokens, and Claude 3.5 Sonnet is priced at around $3.00 per million input tokens. On the other hand, Qwen2.5-Max’s [ricing start at just $0.38 per million input tokens. This distinct cost advantage makes Qwen 2.5-Max attractive, especially for startups and smaller businesses looking to integrate cutting-edge AI within tier-limited budgets.
Below are comparative cost structures for individual and enterprise users of major models
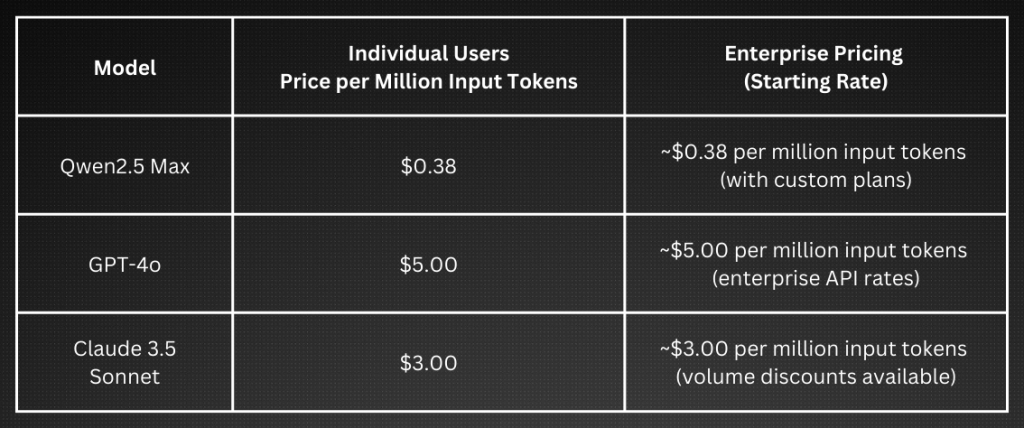
Fig. 5: Cost-benefit of Qwen2.5-max
Note that enterprise plans often include volume discounts, service-level agreements, and custom integrations. These competitive rates allow a broader audience—from individual developers to large enterprises—to access state-of-the-art AI at a fraction of the cost compared to other leading models.
Industry Applications
Alibaba Cloud’s Qwen2.5-Max has been applied in various industry-specific scenarios, leveraging its advanced capabilities to address unique challenges:
1. Text-to-Video Generation: Alibaba Cloud released a new text-to-video AI model through its Tongyi Wanxiang image generation family in September 2024. Through its text-to-video functionality, the model assists advertising education and entertainment industries in creating video content from written descriptions thus simplifying their production workflows.
2. Multimodal Applications: The Qwen2.5 family provides more than 100 open-source multimodal models that work with 29 different languages. The models serve to improve AI functionality in multiple industry sectors through their integration of text and image processing capabilities.
3. Real-Time Data Analysis: The real-time capabilities of Qwen2.5-Max make it suitable for applications that require immediate data processing because of its optimized performance speed. The speed of Qwen2.5-Max allows financial and logistical organizations to conduct immediate data analysis which supports fast operational decisions and flexible business operations.
Conclusion
Qwen2.5-Max represents a breakthrough in AI technology, merging advanced architectural innovations with efficient training methodologies and multimodal capabilities. Its competitive pricing not only makes it an attractive option for businesses seeking state-of-the-art AI solutions but also positions it as a transformative tool for decision support and enhanced operational efficiency across diverse sectors.
As global enterprises increasingly adopt AI-driven strategies to revolutionize their operations, Qwen2.5-Max stands out for its exceptional technical prowess and broad applicability. Its robust performance and scalable design make it a powerful enabler for application developers.
For organizations and professionals eager to harness these cutting-edge capabilities, DataCouch offers customized AI and Generative AI consulting and training solutions. These tailored programs are designed to empower businesses to integrate advanced AI solutions into their workflows, driving digital transformation and ensuring a competitive edge in today’s rapidly evolving technological landscape.