
Quantization, LoRA, and Serving: A Guide to Efficient LLM Deployment
Picture this. Your team just spent six months building a custom large language model for internal use. The model works beautifully in testing. Then comes the bill. Running a 70-billion-parameter model at full precision eats through roughly 280 GB of GPU memory. That is north of $50,000 in hardware just to load the thing, let alone serve it to real users.
Here is the good news. You do not need to spend that kind of money anymore. Three techniques, when used together, can cut your deployment costs by 70% or more while keeping output quality nearly intact. Those techniques are quantization (shrinking the model), LoRA (fine-tuning it cheaply), and optimized serving (running it efficiently at scale).
In simple terms, efficient LLM deployment means getting a powerful AI model into production without burning through your GPU budget, your team’s patience, or your timeline.
The Stanford HAI AI Index Report 2025 found that LLM inference costs dropped 280-fold in just 18 months. That kind of drop does not happen by accident. It happens because smart teams apply the right combination of compression, adaptation, and serving strategies. This guide walks you through all three, with real cost numbers, so you can make better infrastructure decisions for your organization.
Quantization: How to Shrink a Model Without Breaking It
Every AI model stores its knowledge as numbers. A standard model uses 32-bit floating-point numbers (FP32) for each weight. That is extremely precise, but it is also extremely wasteful. Most of that precision is unnecessary for real-world tasks.
Quantization converts those high-precision numbers into lower-precision formats. Think of it like compressing a RAW photo into JPEG. The file gets dramatically smaller, but the image still looks sharp to the human eye.
The math is straightforward. A 70B-parameter model at FP32 needs about 280 GB of memory. Drop to FP16 and it needs 140 GB. Go to INT4 and you are looking at roughly 35 GB. That is an 8x reduction, and it means you can run a massive model on a single consumer GPU instead of a rack of expensive data center hardware.

The Three Methods That Actually Matter in 2025
Not all quantization approaches work the same way. Here is what you need to know about the three that dominate production deployments right now.
| Method | How It Works | Best For | Key Trade-off |
|---|---|---|---|
| GPTQ | Compresses weights layer by layer after training. Handles 175B+ models in about 4 GPU hours. | Offline compression to 3-4 bits for large-scale deployment | High compression, slight accuracy dip on reasoning tasks |
| AWQ | Protects the 1% of weights that matter most based on activation patterns. | Edge devices and latency-sensitive apps | Best accuracy retention at very low bit widths |
| SmoothQuant | Shifts quantization difficulty from hard-to-compress activations to easier-to-compress weights. | Production W8A8 serving at scale | 2x memory savings, 1.56x speed gain |
Research from Qualcomm shows that INT8 quantization delivers up to a 16x boost in performance per watt compared to FP32. And according to published peer-reviewed studies, well-calibrated INT8 and 4-bit quantization typically causes less than 1% accuracy loss on major benchmarks.
The Bottleneck Nobody Talks About: KV Cache
Here is the surprising truth about LLM memory usage. Once you quantize the model weights, the biggest memory hog during inference is not the model itself. It is the key-value (KV) cache.
The KV cache stores intermediate computations as the model generates each token. It grows with every token in the conversation. For long-context applications like document summarization or multi-turn chat, the KV cache can easily consume more memory than the model weights themselves.
Newer techniques like KIVI (2024) enable 2-bit KV cache quantization without any retraining. QServe introduced a combined W4A8KV4 approach that quantizes weights, activations, and KV cache together. Most blog posts and training materials skip this entirely, which is a mistake if you are planning a real production deployment.
When Quantization Hurts More Than It Helps
Not every workload benefits equally. Smaller models under 7 billion parameters are more sensitive to aggressive compression. Tasks that involve complex math or multi-step reasoning tend to degrade faster. And if your application requires near-perfect factual accuracy with zero tolerance for drift, you will want to stick with 8-bit or higher.
The rule of thumb: bigger models tolerate harder compression. A December 2025 study on the Qwen3 model family confirmed that larger models show greater resilience to quantization-induced accuracy loss.
Want your team to master quantization, LoRA, and production-grade deployment from the ground up?
Explore DataCouch's LLM Engineering and Deployment: Architecting, Training & Scaling Generative AI Systems program, a 40-hour hands-on training that covers all three pillars covered in this guide.
LoRA and QLoRA: Fine-Tuning Without the $50,000 Bill
Quantization shrinks the model. But what if you need the model to speak your language? To follow your company’s formatting rules, to understand your industry’s jargon, or to handle domain-specific tasks like medical coding or legal analysis?
That is where fine-tuning comes in. And that is where most organizations hit a wall.
Traditional full fine-tuning updates every single parameter in the model. For a 7-billion-parameter model, that requires 100 to 120 GB of VRAM. According to Introl’s December 2025 analysis, that translates to roughly $50,000 worth of H100 GPUs for a single training run.
LoRA (Low-Rank Adaptation) changes the economics completely. Instead of updating all weights, LoRA freezes the original model and injects tiny trainable matrices into specific layers. You end up training less than 1% of the total parameters while recovering 90 to 95% of full fine-tuning quality.
QLoRA: The $10 Fine-Tune
QLoRA combines LoRA with 4-bit quantization of the base model. It introduces three innovations that matter for budget-conscious teams:
- 4-bit NormalFloat (NF4): A data type specifically designed to preserve information at very low precision.
- Double Quantization: Even the quantization parameters themselves get compressed, saving additional memory.
- Paged Optimizers: When GPU memory spikes during training, optimizer states automatically page to CPU memory instead of crashing.
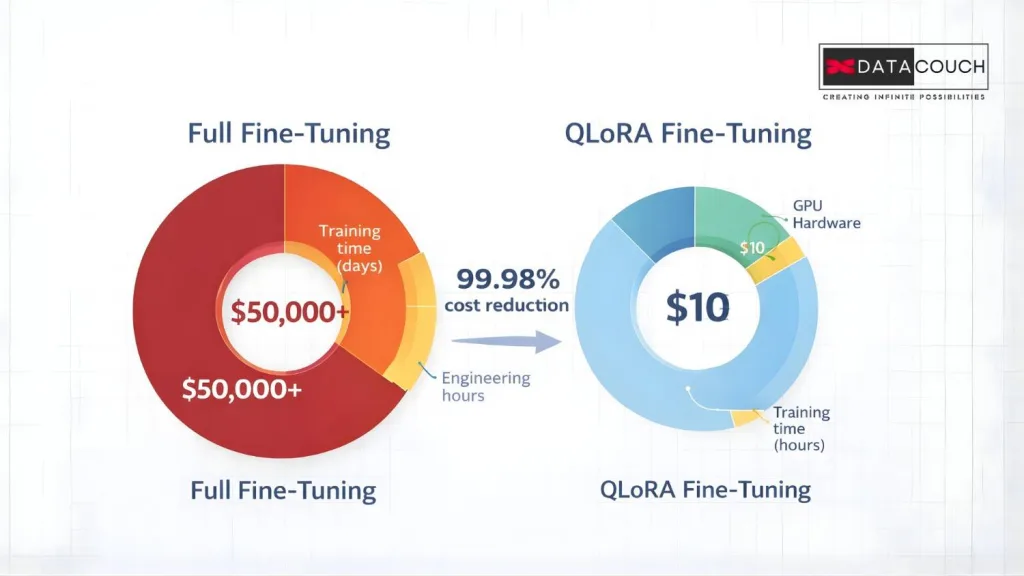
The practical result? You can fine-tune a 70-billion-parameter model on a single A100 80 GB GPU. A 7B model fine-tune costs about $10 on cloud GPUs. The same job with full fine-tuning would require 4 to 8 GPUs and cost thousands.
There is a trade-off worth knowing. QLoRA training runs about 30 to 40% slower than standard LoRA because the forward pass has to convert weights from 4-bit back to 16-bit for computation. For most use cases, the memory savings far outweigh the speed penalty.
The LoRA Variants Most Training Programs Still Ignore
What most people do not realize is that vanilla LoRA is no longer the best option for every situation. The 2025-2026 landscape includes several important variants that upskilling and certification programs are only now starting to cover:
| Variant | What It Does | When to Use It |
|---|---|---|
| DoRA | Separates weight updates into magnitude and direction for better adaptation | Default starting point for new projects (recommended over vanilla LoRA) |
| rsLoRA | Adds a scaling factor that stays stable at high ranks | When you need rank 64+ for heavy domain shift |
| LongLoRA | Uses Shift Short Attention for efficient extended-context training | Training models to handle 32K to 100K+ token contexts |
| QA-LoRA | Quantizes the LoRA adapters themselves during training | Ultra-efficient training and deployment pipelines |
A 2025 study on rank selection found that intermediate ranks of 32 to 64 offer the best balance between quality and stability. That contradicts the earlier default advice of using rank 8, which many guides still recommend. If your team is pursuing certifications in GenAI or MLOps, understanding these nuances sets you apart.
One Base Model, Many Specialists: Multi-LoRA Serving
Here is a pattern that almost no blog post covers, but that enterprise teams are already adopting. Instead of deploying separate models for each department, you deploy one base model and hot-swap lightweight LoRA adapters based on the incoming request.
Your legal team gets a legal adapter. Your medical coding team gets a healthcare adapter. Your engineering team gets a code-generation adapter. All running on the same GPU, the same base model, at the same time.
A May 2025 paper from arXiv introduced FastLibra, a system that manages LoRA adapter and KV cache swapping intelligently. It reduced time-to-first-token by 63.4% compared to existing multi-LoRA systems. That is the kind of improvement that turns a sluggish internal tool into something people actually want to use.
If your developers are building GenAI applications with Python, LangChain, or open-source LLMs, check out Generative AI Using Python: Building Production-Ready Intelligent Applications for a hands-on, engineering-focused path from LLM basics to production deployment.
Serving: Where Good Models Go to Waste (Or Not)
You have compressed the model. You have fine-tuned it for your domain. Now you need to serve it to hundreds or thousands of users without the response times making everyone give up and switch back to email.
This is where most organizations lose money they did not have to lose. Traditional inference frameworks waste 60 to 80% of GPU memory on unused KV cache allocations. They process requests in fixed batches, leaving the GPU idle whenever some requests finish before others.
The Framework Showdown: vLLM vs TGI vs the New Players
A November 2025 benchmarking study compared the two most popular open-source serving frameworks head to head. The results were clear:
| Framework | Strengths | Best For |
|---|---|---|
| vLLM | PagedAttention eliminates KV cache waste. Up to 24x throughput vs standard serving. Powers inference at Meta, Mistral AI, Cohere, IBM. | High-concurrency production: chatbots, APIs, batch processing |
| HuggingFace TGI (v3) | Prefix caching gives 13x speedup on 200K+ token prompts. Lower tail latency for interactive single-user scenarios. | Long-context RAG workloads, document summarization |
| SGLang | RadixAttention plus structured generation language for complex output control. | Agentic workflows, multi-modal tasks, JSON/code generation |
| NVIDIA Dynamo | Disaggregated prefill and decode stages. NIXL library for fast interconnects. | Data center-scale deployments needing ultra-low latency |
Stripe’s migration to vLLM tells the story best. They cut inference costs by 73% while processing 50 million daily API calls on one-third of their previous GPU fleet. That was not a research experiment. That was a production deployment serving real users at scale.
Speculative Decoding: The 2.5x Speed Trick
Standard LLM inference generates tokens one at a time. Each token requires loading the full model weights from memory, which is painfully slow for large models.
Speculative decoding flips this on its head. A small, fast draft model guesses several tokens ahead. The large model then verifies those guesses in a single parallel pass. When the draft model guesses correctly (and for predictable outputs like code or JSON, it often does), you skip multiple slow generation steps.
QuantSpec, presented at a leading ML conference in 2025, combines speculative decoding with 4-bit KV cache quantization. It achieves over 90% acceptance rates and roughly 2.5x end-to-end speedup. Almost no training program or certification covers this technique yet, which makes it a real competitive edge for teams investing in upskilling.
Putting It All Together: The Unified Deployment Pipeline
The real power comes from combining all three techniques in sequence, not picking just one. Here is the pipeline that forward-thinking engineering teams are running right now:
- Start with a strong open-source base model (Llama 3.1, Qwen 3, Mistral).
- Apply QLoRA fine-tuning on your domain data using a single A100 or even an RTX 4090.
- Merge the LoRA adapter back into the base model (this adds zero inference latency).
- Quantize the merged model to 4-bit using AWQ or GPTQ.
- Deploy through vLLM or SGLang with PagedAttention, continuous batching, and prefix caching enabled.
- Add speculative decoding for structured output workloads.
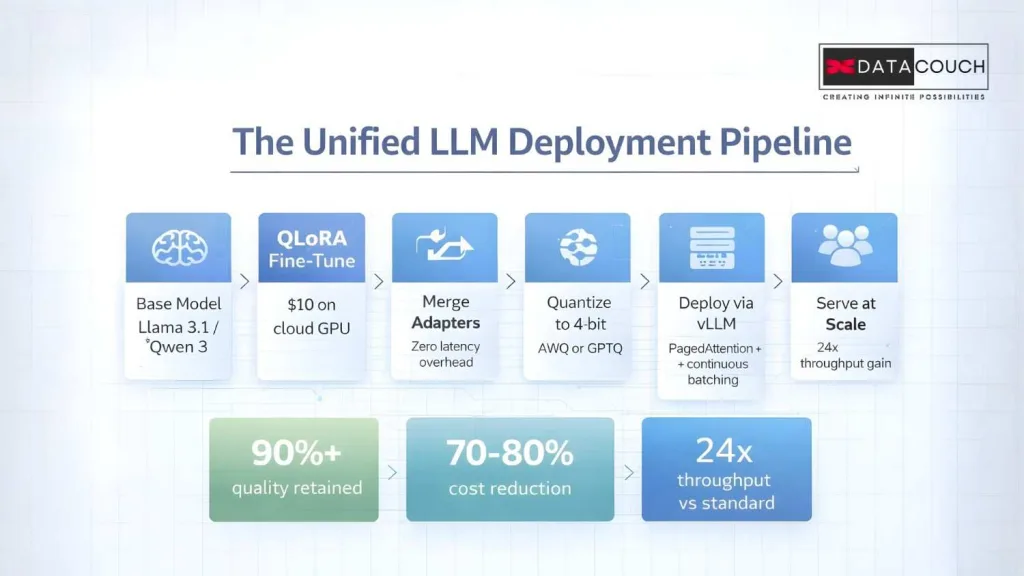
This pipeline takes a model that would cost $50,000+ in GPUs to run at full precision and puts it on hardware costing a fraction of that, while retaining 90%+ of the original quality.
The Cost Math Your CFO Needs to See
| API (GPT-4o) | Self-Hosted 70B (Quantized) | Self-Hosted 7B (Quantized) | |
|---|---|---|---|
| Cost per 1M tokens | $2.50-$10.00 | ~$0.40 | ~$0.40 |
| Monthly at 50M tokens/day | $15,000-$45,000+ | $2,500-$4,000 | $300-$500 |
| Data stays on-prem? | No | Yes | Yes |
| Custom fine-tuning? | Limited | Full LoRA/QLoRA | Full LoRA/QLoRA |
| Break-even volume | N/A | ~2M tokens/day | Almost always cheaper |
The Stanford HAI 2025 report puts these numbers in perspective: inference costs for GPT-3.5-class performance dropped from $20 per million tokens in late 2022 to $0.07 by October 2024. That 280-fold decline was driven largely by the techniques covered in this guide, namely smaller optimized models, better quantization, and more efficient hardware utilization.
Building AI-powered applications is just as much about development workflow as it is about models. DataCouch's Advanced AI Engineering: Vibe Coding course trains your team on AI-driven development practices that accelerate how you build, test, and ship intelligent software.
What Comes Next: The 2026 Frontier
The field is moving fast. Here are the developments worth tracking:
- FP4 quantization: New Blackwell-architecture GPUs natively support 4-bit floating-point operations, promising even greater savings without accuracy loss.
- Mixed-precision by layer: Instead of one quantization level for the entire model, different layers use different bit widths based on their sensitivity.
- LoRA for Mixture-of-Experts (MoE): The SGLang 2026 Q1 roadmap includes LoRA support for MoE layers, enabling fine-tuning of the most efficient model architectures.
- Disaggregated serving: Separating prompt processing from token generation onto different GPU pools for better resource allocation.
For teams investing in training and upskilling programs, these trends point to a clear message. The professionals who understand the full stack, from quantization math to serving infrastructure, will be the ones leading AI deployment decisions next year.
Key Takeaways
- Quantization cuts model memory by 75 to 90% with less than 1% accuracy loss when done correctly. The KV cache, not the model weights, is often the real memory bottleneck during inference.
- LoRA and QLoRA reduce fine-tuning costs from $50,000+ to under $10 for small models. The 2025 variant landscape (DoRA, rsLoRA, LongLoRA) goes well beyond the basics.
- Modern serving frameworks like vLLM eliminate 60 to 80% of GPU memory waste. Speculative decoding adds another 2 to 3x speedup on top of that.
- The unified pipeline of quantize, adapt, and serve is the real competitive advantage. Individual techniques help. Together, they transform the cost equation entirely.
The gap between organizations that deploy LLMs efficiently and those that overspend on GPU bills keeps growing wider. The difference is not access to bigger hardware. It is knowledge.
So here is the question worth asking: does your team have the skills to deploy AI efficiently, or are you still paying full price for something that could cost 90% less?



