
Tarun Jain
A data scientist with a strong focus in AI/ML, this individual is recognized as a Google Developer Expert and actively contributes to the open-source community.
Being able to ask questions directly to your company’s knowledge base, internal documents, and even your notes—and get accurate, context-aware answers—can be a game changer. Though, Large Language Models (LLMs) are trained on the generic data from Internet with billions of parameters, they lack the unique insights hidden in your organizational data. Instead of relying on generic information from the base LLM, what if you can interact with insights rooted in your own data? Wouldn’t it be a game changer?
This approach is known as Retrieval-Augmented Generation (RAG). It connects large language models (LLMs) with your internal content to produce responses that are both relevant and grounded. In this guide, we’ll explore what RAG is, learn about the core components required to build a RAG workflow, and walk you through how to build a no-code chatbot using n8n that allows you to chat with your private business data—no engineering required.
What You’ll Learn in This No-Code RAG Tutorial?
Being able to ask questions directly to your company’s knowledge base, internal documents, and even your notes—and get accurate, context-aware answers—can be a game changer. Though, Large Language Models (LLMs) are trained on the generic data from Internet with billions of parameters, they lack the unique insights hidden in your organizational data. Instead of relying on generic information from the base LLM, what if you can interact with insights rooted in your own data? Wouldn’t it be a game changer?
This approach is known as Retrieval-Augmented Generation (RAG). It connects large language models (LLMs) with your internal content to produce responses that are both relevant and grounded. In this guide, we’ll explore what RAG is, learn about the core components required to build a RAG workflow, and walk you through how to build a no-code chatbot using n8n that allows you to chat with your private business data—no engineering required.
By the end of this guide, you’ll understand how to build a no-code AI chatbot integration using n8n and how this approach enables direct interaction with your internal data. Specifically, you’ll learn how to:
- Identify the limitations of traditional Large Language Models (LLMs) when it comes to querying private data or up-to-date information.
- Understand the concept of Retrieval Augmented Generation (RAG) and how it improves the accuracy of responses by grounding them in your own content.
- Break down a typical RAG workflow into its core components—from data preprocessing to vector storage and retrieval.
- Use embedding models and vector stores to represent and store your documents efficiently.
- Set up and deploy a chat-style AI assistant with n8n to query internal files like reports, policies, or meeting notes—without writing code.
This tutorial is ideal for HR teams, operations leads, and functional business managers looking to explore no-code AI integrations and LLM-powered automations.
What are the issues with Large Language Models?
Large Language Models have changed how we interact with AI, but they still come with limitations. One of the biggest challenges is their Knowledge cutoff. These models are trained on data up to a certain point in time. So if you ask about recent events or updates, chances are the model won’t know. It might either skip the answer or give you something vague that’s no longer valid.
Another limitation is access to private data. LLMs don’t have access to your internal files, meeting notes, or sales reports unless you manually provide that info in the prompt, which isn’t scalable due to context limits. If you ask, “What was discussed in last week’s team meeting?” or “Summarize our latest Q3 review,” the model won’t have a clue unless it saw that data.
Lastly, there’s the issue of Hallucinations and Generic replies. When LLMs don’t know something, they can still generate answers that sound right but are completely made up. This gets worse when the question requires specific internal knowledge. The model may give a general explanation instead of one rooted in your data. That’s where Retrieval-Augmented Generation (RAG) becomes useful. It bridges the gap between static knowledge and dynamic, custom data.
How Retrieval-Augmented Generation (RAG) Works with Your Data?
Retrieval Augmented Generation (RAG) is an advanced natural language processing (NLP) technique designed to address a key limitation of traditional large language models (LLMs): the inability to retrieve real-time, private, or specialized information. Unlike relying on static, pre-existing knowledge, RAG improves the accuracy and relevance of AI-generated responses by incorporating real-time business data into the generation process.
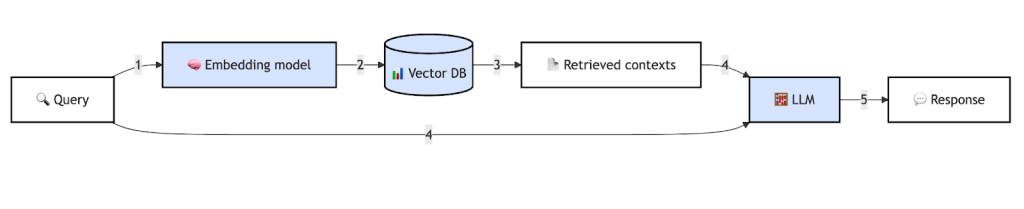
At a high level, a RAG workflow connects an LLM to an external knowledge source—typically a vector database—that stores your internal documents in an AI-searchable
How RAG Works — Two Core Steps
At its core, RAG combines two main processes:
- Retrieval
Before responding to a user query, the system retrieves the most relevant information snippets from your defined knowledge base—such as PDFs, reports, meeting notes, or web content. These are stored as vector embeddings in a vector database like Pinecone, Chroma, or FAISS.
This step works like an “open-book exam”—the system actively looks up facts related to the query instead of guessing, maintaining the highest level of accuracy.
Generation
The retrieved snippets of information are passed on to the LLM along with the original user query. This allows the model to generate a response that is both coherent and context-aware, grounded and anchored directly in your enterprise content and not on general/generic internet knowledge.
Why Use Retrieval-Augmented Generation?
By allowing the LLM to consult your private data, RAG offers several key benefits:
- Reduces hallucinations in AI models by grounding responses in verified content
- Provides up-to-date, domain-specific answers—essential for dynamic fields like HR, finance, legal, and healthcare
- Enables no-code teams to create LLM-powered tools that respect internal knowledge boundaries
A well-configured RAG system will respond only using the data available in its enterprise vector store. If a query falls outside the given context, as a well-grounded RAG LLM returns a confident “I don’t know” instead of guessing (meaning fabricating) a plausible-sounding (but incorrect) answer. For instance, if your dataset includes medical records and someone asks, “What is a black hole?”, then instead of depending only on pre-trained knowledg, the model will respond appropriately. It would acknowledge that the topic isn’t within its scope making the output more relevant and trustworthy.
This behavior, of designating the retrieved context as the model’s primary source of truth, is referred to as the “Augmented” in Retrieval-Augmented Generation. It’s a powerful way to build accurate, trustworthy AI assistants and workflows using your own content and knowledge-base.
Real-World Use Cases: HR and Account Managers Chatting with Their Data
Retrieval-Augmented Generation (RAG) is more than just a technical concept—it is helping address real operational pain points.
- HR teams often spend valuable time digging through policy manuals or onboarding documents to answer repetitive employee questions. They can now instantly answer most employee questions without opening a single PDF. By building an HR assistant chatbot using n8n, you can relieve them of this drudgery.
- On the other hand, Account managers struggle with accessing past QBRs (Quarterly Business Reviews), client agreements, or CRM updates scattered across systems and formats. They can now ask the account management bot built using n8n to summarize past QBRs, check contract clauses from historical notes, even refer to the past interactions recorded in CRM, emails, or Slack chats.
With no-code RAG chatbots built in n8n, executives can create internal AI assistants to surface domain information instantly, enhance responsiveness, and improve accuracy and productivity across functional departments.

Use Case 1: Automate HR Document Queries with RAG and AI
Pain Point:
HR managers often lose hours manually searching for appropriate and relevant facts through scattered employee handbooks, policies, onboarding docs, compliance reports, or past feedback records.
Chatbot Solution:
By building a no-code HR chatbot for internal policy search using n8n and RAG, your HR team can query internal content conversationally.
Example prompt: “What’s the paternity leave policy for contract employees?”
Outcome: The bot retrieves the exact paragraph(s) from the latest HR manual and elaborates it in simple (lay) terms for the reader. No need to dig through files or chasing colleagues via emails!
Use Case 2: Account Management Chatbot for Client Data Retrieval
Pain Point:
Account managers frequently need to pull details from past communications to summarize QBRs, review contract terms, or pull status updates. This information is typically spread across PDFs, emails, and CRM entries – making it virtually impossible to manage multiple accounts simultaneously.
Chatbot Solution:
With a no-code sales assistant built using RAG and n8n, account teams can automate QBR summaries and retrieve client-specific insights from internal folders or structured docs.
Example queries may include “Summarize the last QBR with Acme Corp” or “When is our contract up for renewal with XYZ Ltd?”
Outcome: The sales assistant bot can quickly searches through meeting notes, contracts, and slide decks stored in your vector database. By delivering precise answers in seconds, the n8n chatbot can reduce administrative overhead and help improve responsiveness.
Step-by-Step Breakdown of the RAG Pipeline for No-Code Builders
To build a chatbot that can “talk” to your internal documents, you need to set up a Retrieval-Augmented Generation (RAG) pipeline. At each step, this process transforms raw data into a format your LLM-powered chatbot can quickly search and use to generate relevant, accurate answers.
By understanding these components and steps, you can either use a no-code tool like n8n or even code to orchestrate the entire process.
1. Load and Preprocess Your Data
The first step is to ingest the raw content including enterprise documents, PDFs, documents, manuals, transcripts of YouTube and other videos, website text, and even CRM database records. This will help you prepare the data for processing.
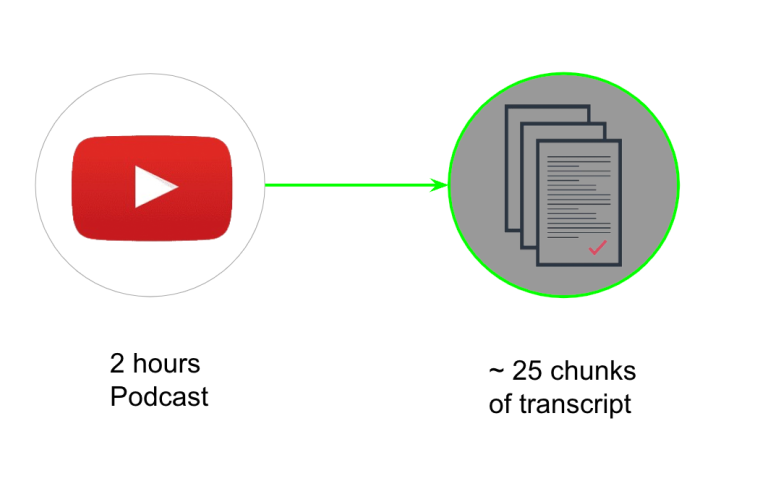
Since LLMs are constrained by context window limitations, longer documents are broken into smaller, digestible “chunks.” This chunking improves both embedding efficiency and retrieval accuracy later in the pipeline allowing for quick and effective searching for specific information in smaller, focused data segments.
2. Embed the Text into Vectors
Once the content is broken down into manageable chunks, each piece is converted into a numerical vector using an embedding model. These text embeddings capture the semantic meaning of the content, enabling machines to process and compare the information.
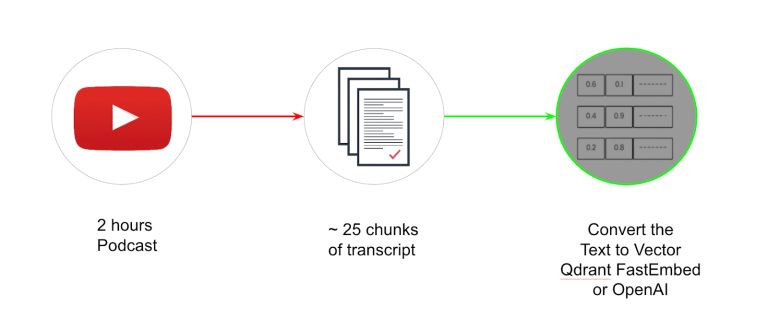
You can use closed-source embedding models from OpenAI, Google, or open-source libraries like Sentence Transformers for generating dense vectors of data. Chunks having similar content will generate similar mathematical vectors, thereby allowing the system to match queries to relevant passages later (something akin to pattern matching, but not exactly the same).
3. Store Embeddings in a Vector Database
The generated vectors (along with their source text) are stored in a vector database, such as Pinecone, ChromaDB, Weaviate, or FAISS.

These databases are optimized for semantic similarity searches—meaning they can rapidly find the most relevant pieces of information, even across millions of chunks.
4. Retrieve Relevant Chunks Based on User Query
When a user types a question, the system first converts that query into an embedding, using the same embedding model applied earlier while creating the embeddings. It then compares this query vector with stored vectors to find the closest matches.
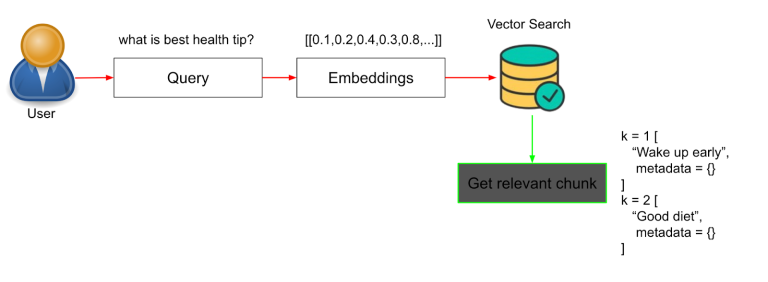
This process identifies and retrieves the most relevant content snippets from your data, based on semantic meaning (embeddings that are closest mathematically), not just keyword matching.
At the retrieval step, the most relevant information from your indexed data is retrieved based on the user’s query.
5. Augment the Prompt and Generate the Response
Finally, the retrieved content chunks are combined with the original query to create a prompt. This prompt is sent to a large language model (LLM) like GPT-4 or Claude, instructing it to generate an answer using only the supplied context.
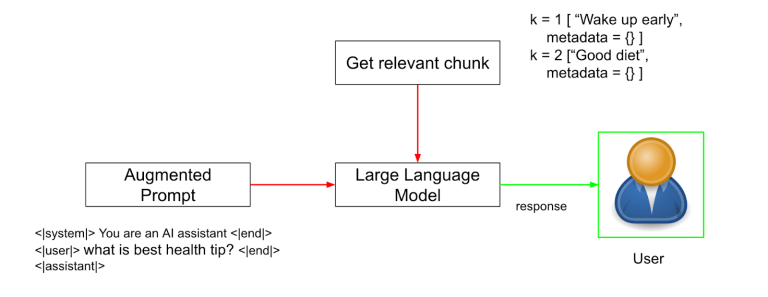
The prompt essentially instructs the LLM to “Answer the user’s question: ‘[original query]’ using the following information: ‘[retrieved text chunks]’.“
For example:
“Answer the question: ‘What are our Q3 KPIs?’ using the following information: [retrieved text from internal datasets goes here].”
Because the model is “grounded” in retrieved context, it reduces hallucination and produces a factual, context-aware response that reflects your internal knowledge—not generic web content.
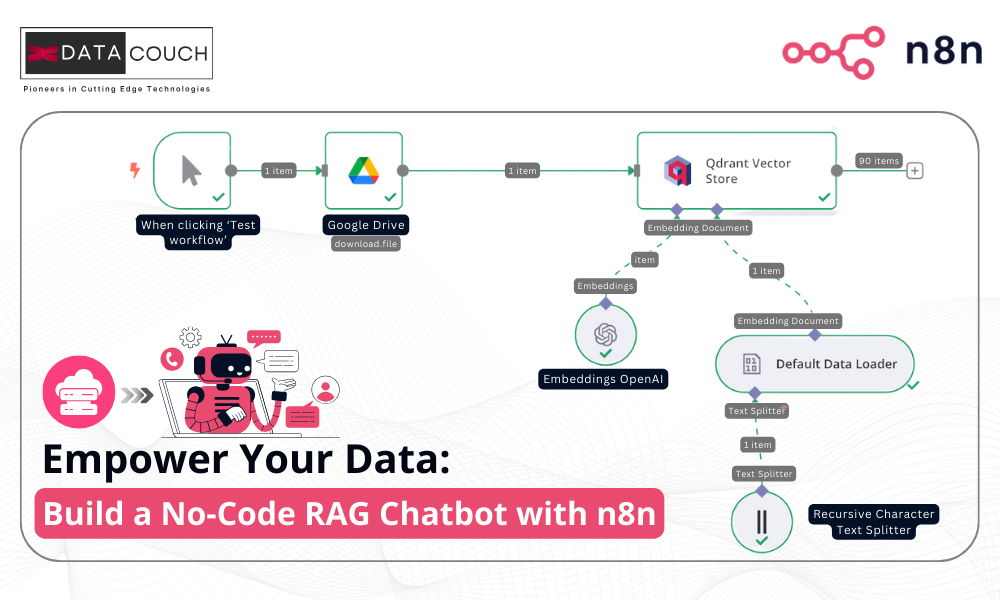
How to Chat with Your Data: Building RAG Workflow Using n8n
This section will walk you through creating a no-code AI assistant that can answer questions based solely on a PDF stored in your Google Drive. The assistant uses Retrieval-Augmented Generation (RAG) to ensure all responses are grounded in your document—not generic internet data.
Let’s break down the setup into simple, actionable steps.
Step 1: Set Up Your Free n8n Cloud Account
To begin building your workflow, start by registering for an n8n Cloud account, which is totally free. After entering your login credentials, you’ll be prompted to complete a brief questionnaire. Once finished, click the “Start Automating” button to proceed to your n8n Cloud workspace.
Step 2: Start the Workflow & Trigger Manually
To upload your document into a vector database, you first need to start a workflow in n8n.
1. In your n8n dashboard, click the ‘+’ icon and select Add another trigger.
2. From the list of options, choose Trigger Manually. This makes it easy to run your flow with a click during testing.

Step 3: Connect Google Drive and Upload Your Document
Next, upload your chosen PDF to Google Drive if it’s not already there. You’ll then integrate Google Drive with n8n to allow your workflow to access the file.
Here’s how to connect your Drive via OAuth:
1. Go to the Google Cloud Console, create a new project (you can create up to 12 without billing).
2. In the left sidebar under APIs & Services, enable the Google Drive API Library.

3. Once again, from the left sidebar under APIs & Services, open the OAuth consent screen and create an OAuth Client ID and Client Secret (choose “Web application” as the app type).
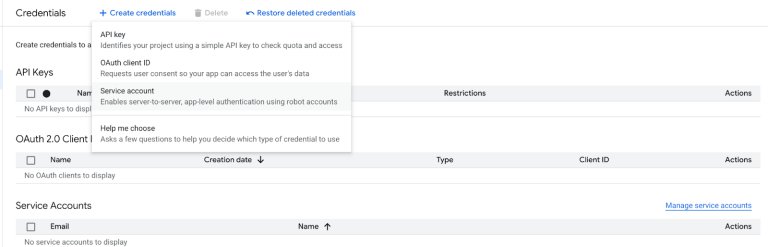
4. You will then be prompted to add Authorized Redirect URIs. Go to n8n, select the Google Drive component, click on +, again search for the Google Drive node, select the Download File action, and copy the redirect URI shown there.
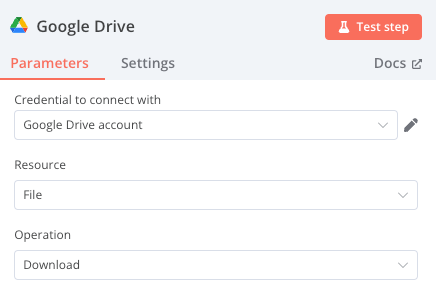
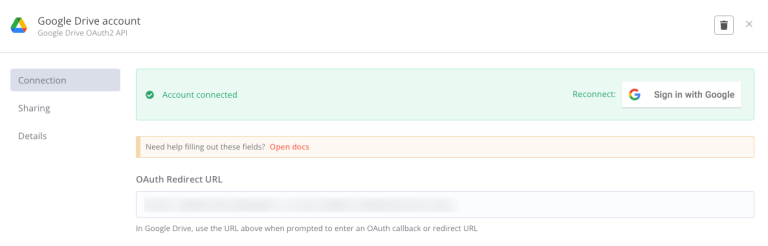
5. After adding the Google Drive component, select Edit to configure Google Drive credentials.
6. Paste this URI into your OAuth setup in the Google Cloud Console.
7. Once you attach the direct URL, the OAuth Client ID is set.
8. Once your credentials (Client ID and Client Secret) are generated, paste them back into the Google Drive credentials section in n8n.
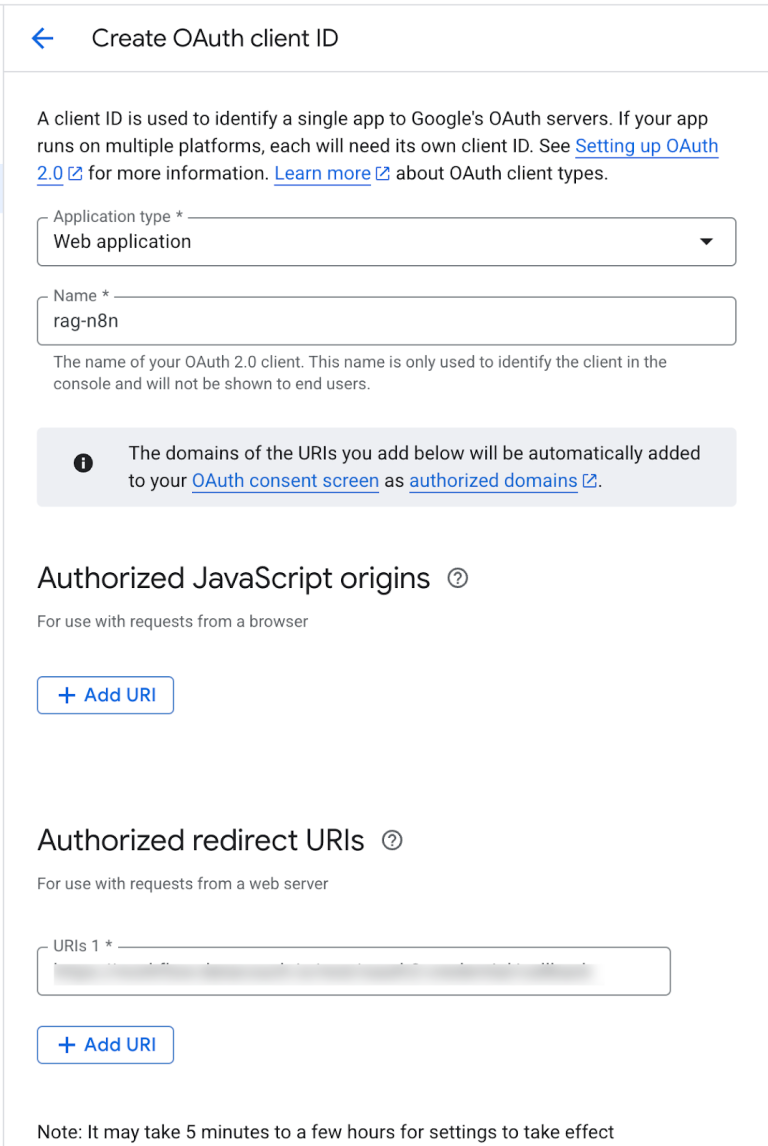
This completes the Google Drive integration—your workflow is now ready to access and process your PDF document.
Step 4: Set Up Your Vector Database (Qdrant)
In a RAG pipeline, a vector database is essential to:
- Store the embedded text chunks
- Retrieve relevant information during queries
We’ll use Qdrant Cloud, a popular and easy-to-integrate no-code vector store.
To set up Qdrant:
1. Create a free account at Qdrant Cloud.
2. Create a new cluster and note the API key and endpoint URL (within the cURL command it starts with https and ends in :6333).
3. Open the cluster’s dashboard, go to the Console, and run the following code to create a collection (e.g., n8n). Think of the collection name as a unique identifier – every time the data is changed, we need to create a new collection name. Run the following code:
PUT /collections/n8n
{
“vectors”:{
“size”: 1536, “distance”: “Cosine” }
}
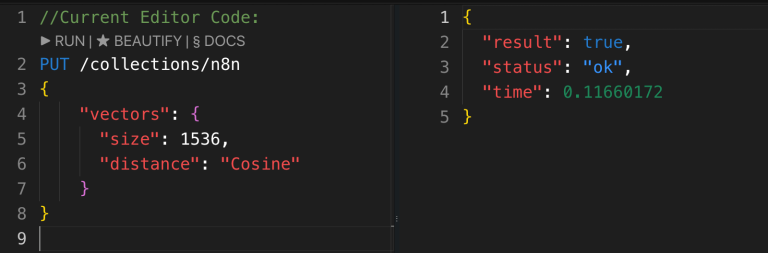
4. Once confirmed (you’ll see true as a response), return to n8n.
5. Add the Qdrant Vector Store node, select the correct collection name (n8n), and paste your Qdrant API key and URL.
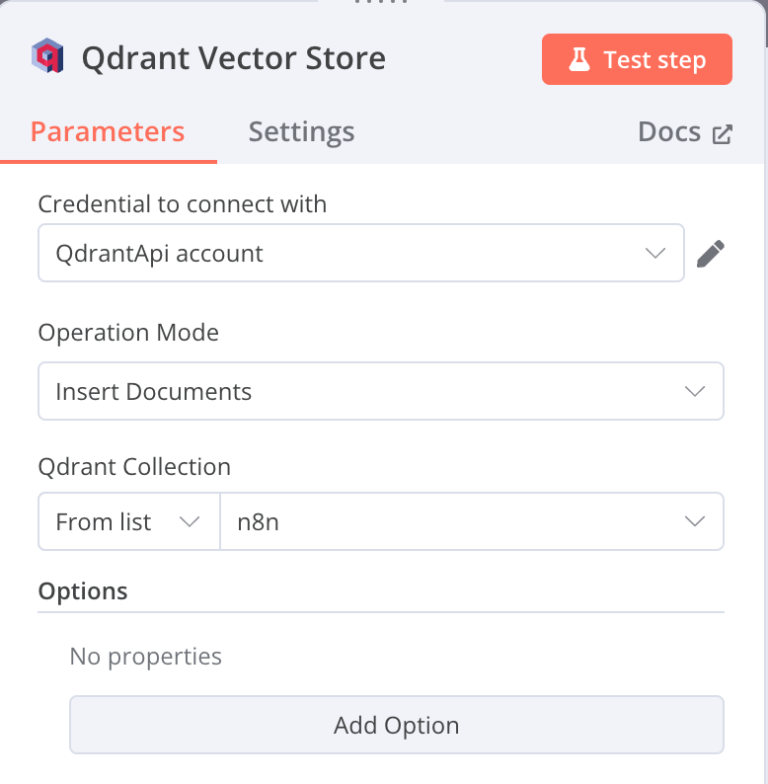
Your workflow is now ready to store vectorized data and enable semantic search.
Step 5: Embed and Index Your Data into the Vector Store
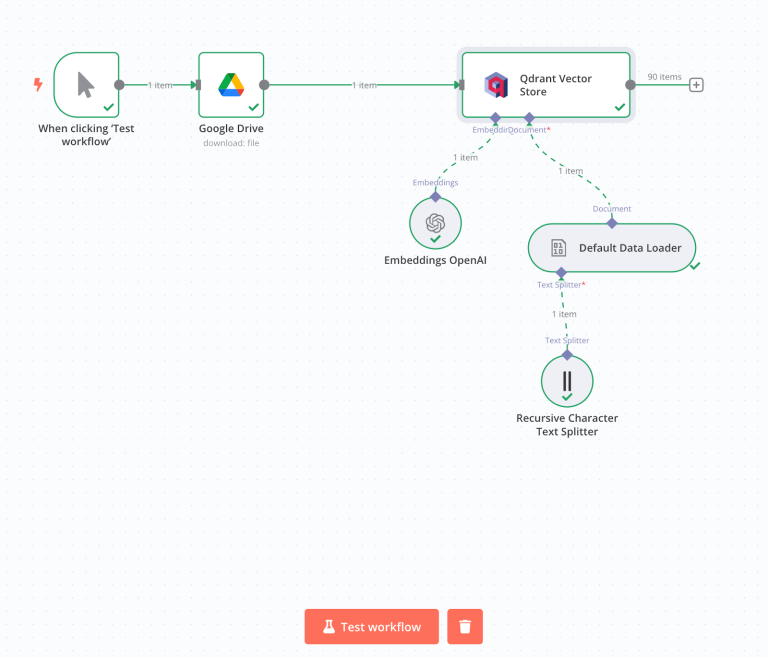
Now that Qdrant is connected, it’s time to index your document. In n8n, click the + icon below the Qdrant Vector Store node and add two components:
- Embedding Model – Choose the same model you’ll use for the user query later (e.g., OpenAI or Gemini).
- Document Loader – Select Default Data Loader and apply the Recursive Character Splitter. This tool breaks the document into chunks, making it easier for the model to retrieve meaningful responses during search.
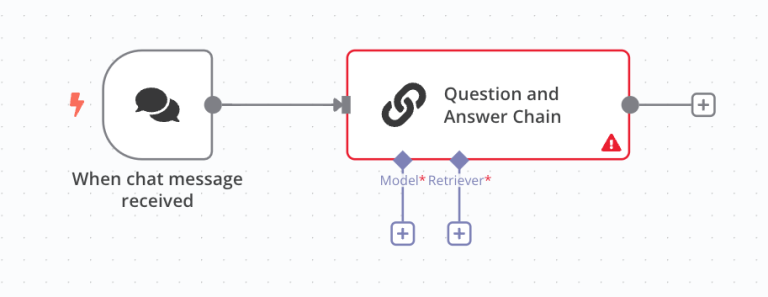
Step 6: Create the Question-and-Answer Workflow
Now you’ll build the core of your RAG chatbot workflow—a simple interface where a user enters a question and receives an answer pulled directly from your indexed document. Add a Q&A Chain component to your n8n flow. This chain connects your model and vector store to generate context-grounded responses to each query.
Step 7: Connect the Model and Define the Retriever
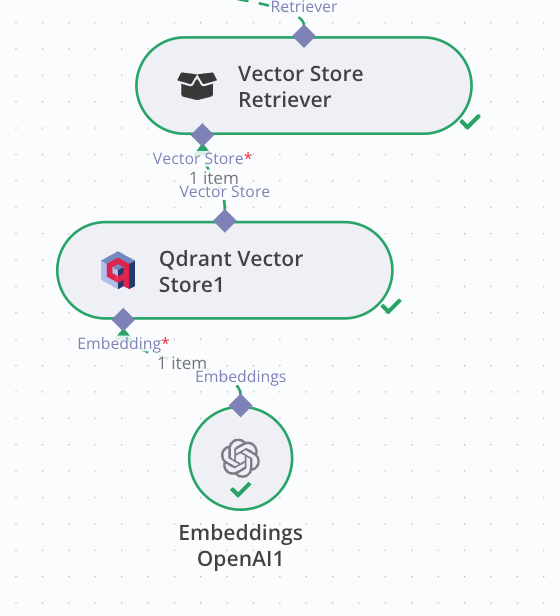
To complete the Q&A chain, you’ll need to add two components:
- A Generator (your LLM of choice) – we’ll use Gemini, connected via API from Google AI Studio. Click `+` and select Gemini.

- A Retriever (Vector Store) – select Qdrant and set the retrieval limit to 4 chunks.
NOTE: Use the same embedding model as the one used during indexing. A mismatch here can result in irrelevant answers or errors. Ensure the collection name in Qdrant matches exactly (e.g., n8n).
As all queries get converted into embeddings, any mismatch in the the embedding models can lead to errors.
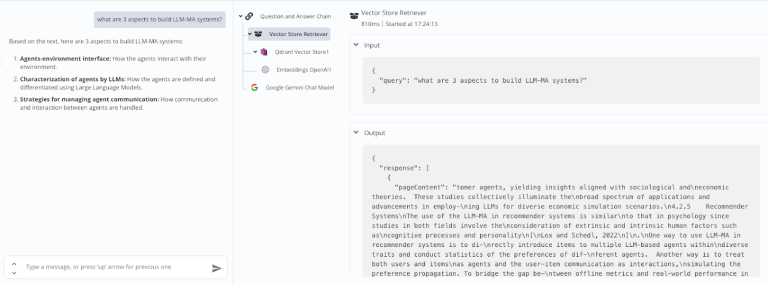
Step 8: Test the Chat and Submit a Prompt
Open the chat interface in n8n and enter a test question—something relevant to your PDF content.
If the system returns a meaningful, document-based answer, congrats! You’ve successfully built a no-code RAG chatbot using n8n that can chat with your private data in real time.
Recap: What You Built
At this point, you’ve connected your document to an LLM using a Retrieval-Augmented Generation pipeline—all without writing a single line of code. With n8n, vector databases like Qdrant, and your own internal content, you’ve built a secure, intelligent chatbot that actually understands your data.
Final Words: From Raw Data to No-Code AI Assistant
In this guide, we explored how to build a no-code RAG chatbot using n8n, breaking down each step of the Retrieval-Augmented Generation process—from loading and chunking your documents, to embedding them into a vector database, and finally generating context-aware responses using an LLM.
By connecting large language models to your own internal knowledge base, RAG enables more accurate, trustworthy, and private interactions with your data. Whether you’re in HR, sales, or operations, this approach empowers you to create scalable AI assistants that reduce manual work and unlock hidden insights—all without writing a single line of code.
You’re now ready to bring the power of Retrieval-Augmented Generation into your workflows and automate knowledge access like never before.