
Introduction
Data Lakes built using Hadoop framework were lacking a very basic functionality i.e. ACID compliance. Hive tried to overcome some of the limitations by providing update functionality but the overall process was messy. Databricks (the company behind Spark) came up with a unique solution i.e. Delta Lake. Delta Lake enables ACID transactions over existing Data Lakes. It can seamlessly integrate with many Big Data Frameworks like Spark, Presto, Athena, Redshift, Snowflake etc. Let’s explore this interesting technology more.
Learning Objectives
- What is Delta Lake?
- Why to use Delta Lakes?
- Parquet v/s Delta Lakes
- Delta Lake Architecture
- How does Delta Lake work?
- How to use Delta Lakes with a working example?
What is Delta Lake?
It is an Open source storage layer that provides reliability to the data lakes. Delta Lakes provides ACID(Atomicity, Consistency, Integrity and Durability) properties, scalable metadata handling, and unifies streaming and batch data processing. It runs on the top of data lakes and it is fully compatible with Spark APIs. Data in Delta Lake is stored in Parquet format. It enables Delta Lake to leverage the efficient compression and encoding schemes that are native to Parquet.
Why to use Delta Lakes?
Here are the key reasons for using Delta Lake –
- Delta Lake brings ACID transactions to your Data Lakes. The readers will never see inconsistent data.
- Delta Lake treats metadata just like data. Delta Lake can handle petabyte-scale tables with billions of partitions and files at ease, hence, it doesn’t suffer from Small file problem like HDFS.
- It is both, batch table as well as streaming source & sink.
- It provides the ability to specify your schema and enforce it. This helps to prevent the bad data from causing corruption.
- Delta Lake transaction log records details about every change made to data providing a full audit trail of the changes.
- Anyone can use Delta Lake with their existing data pipelines with minimal change as it is fully compatible with Spark, the commonly used big data processing engine.
Parquet v/s Delta Lakes
Delta lake is a wrapper over Parquet data format but it offers some additional features on top of Parquet. Here are the differences –
ParquetDelta LakesColumnar Data StorageStorage layer with ACID transactionType specific encodingScalable metadata handlingNo Data Versioning SupportData Versioning AvailableAvailable to any project in the Hadoop ecosystem, regardless of the choice of data processing frameworkAvailable to Spark data processing framework only. It integrates with Presto, Athena etc
Delta Lake Architecture
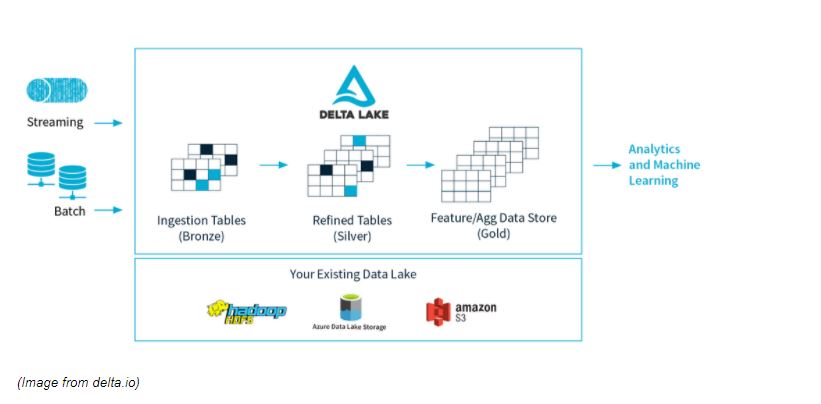
Overall Delta Lake Architecture has been divided into 3 zones. Here Bronze tables serve as the prototypical lake of data, where massive amounts of data trickle in continuously. When it arrives, it’s dirty because it comes from different sources, some of which are not so clean.
From there, data flows constantly into Silver tables, like the headwaters of a stream connected to the lake, rapidly moving and constantly flowing. As Data flows downstream, it is cleaned and filtered by the twists and turns of the various functions, filters and queries, becoming purer as it moves.
By the time it reaches the data processing downstream i.e. our Gold tables, it receives some final purification and stringent testing to make it ready, because consumers i.e. ML algorithms, Data Analysis, etc. are very picky and will not tolerate contaminated data.
How does Delta Lake Work?
For understanding the working of the Delta Lakes, there is a need to understand the working of Transactional Logs. As the transactional log is the common thread that runs through many of its most important features, including ACID transactions, scalable metadata handling, time travel, etc.
Whenever a user executes any modified command, Delta Lakes breaks it down into a series of steps composed of one or more actions.
The list of these actions are:
- Add File: It adds the data file
- Remove File: It removes the data file
- Update Metadata: It updates the table metadata.
- Set Transaction: It records that a structure streaming job created a micro-batch with ID
- Change Protocol: Makes more secure by transferring Delta Lakes to the latest securing protocol.
- Commit Info: It contains the information about the Commits.
How to use Delta Lakes with a working example?
In order to gain a quick understanding of Big Data technologies then you may enroll for our flagship course i.e. “Big Data Crash Course”. During the course, you will be setting up Spark cluster on Dataproc on Google Cloud Platform. If you are looking for gaining an Architectural understanding of data then you may enroll in another interesting course i.e. “Big Data for Architects”.
Delta Lakes required Apache Spark 2.4.2 or above version. You can run it in two ways:
- Run interactively: Start the Spark shell (Scala or Python) with Delta Lake and run the code snippets interactively in the shell.
- Run as a project: Set up a Maven or SBT project (Scala or Java) with Delta Lake, copy the code snippets into a source file, and run the project.
Run Interactively
For running the Delta lake on interactive pyspark or scala spark-shell. You just required Apache Spark on your machine.
Run Pyspark with delta package: pyspark –packages io.delta:delta-core_2.11:0.6.1
Run spark-shell with delta package: spark-shell –packages io.delta:delta-core_2.11:0.6.1
Run as a Project
- If you are creating a maven project then you have to add the following dependencies in POM file:
- You can include Delta Lakes in SBT projects by adding the following line to your build.sbt file: libraryDependencies += “io.delta” %% “delta-core” % “0.6.1”
- In python projects, if you include Delta Lakes then add the following lines:
Create Table:
Pyspark:

Scala:
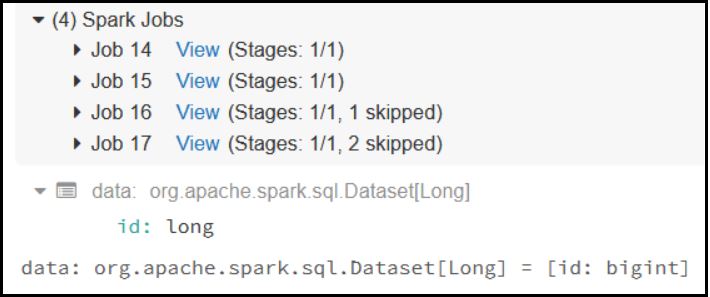
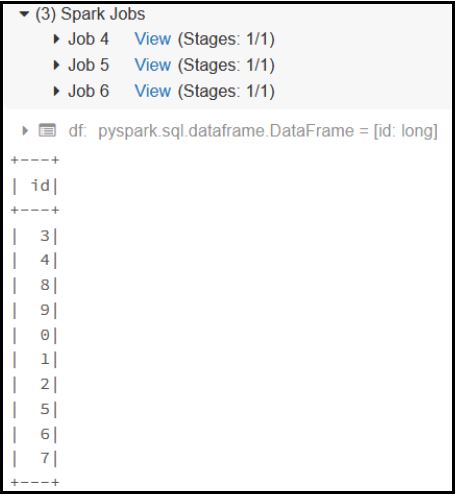
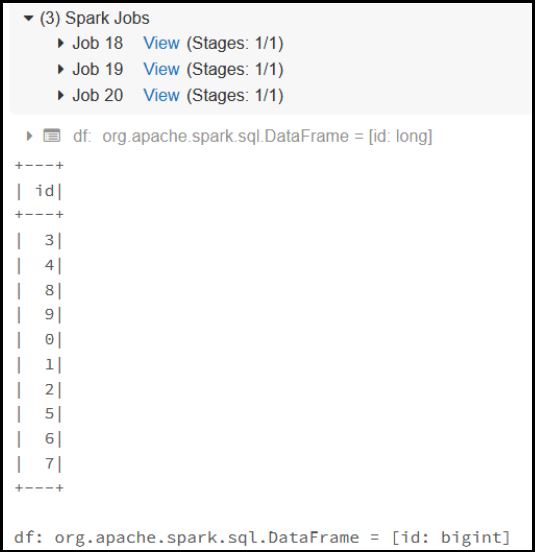
Read Table:
Pyspark:
Scala:
Update Table:
Pyspark:
Scala:
Want to learn more about Delta Lake with hands-on experience? Check out our free meetup session recording here:
Did you like our video? Want to explore more such content related to the latest technologies? Join our meetup family of having 3500+ members, for re-equipping yourself with various new technologies for free. Click here now to join our knowledge-sharing family.
Conclusion
Delta Lakes are the open-source data storage layer, which is compatible with Spark APIs to provide ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. For using Delta Lakes, your system must have Apache Spark version 2.4.2 or above.
