Neo4j for Enterprise AI: Why Graph Databases Are the Missing Layer in Most AI Strategies
What is Graph RAG? Graph Retrieval-Augmented Generation combines a knowledge graph with a large language model. Instead of retrieving text chunks that are semantically similar to a query, it retrieves entities and the relationships between them, giving the AI the context to answer questions that require understanding connections, not just finding similar sentences.
Most enterprise AI strategies have a context problem, and most organisations do not realise it yet.
The standard approach to building AI applications on enterprise data is vector search: convert documents to embeddings, store them in a vector database, retrieve the most similar chunks when a user asks a question, and pass those chunks to a language model to generate an answer. This approach works well for simple question-answering. It breaks down the moment the question requires understanding relationships between entities rather than similarity between text passages.
MIT research found that lack of contextual learning is one of the top reasons why 95% of all generative AI pilots fail to reach production. Gartner states directly: “Without knowledge graphs and semantic enrichment, your data fabric will not provide the rich, contextual, integrated data necessary to avoid hallucinations in GenAI and AI.” Knowledge graphs are not a competing technology to large language models. They are the context layer that makes large language models reliable in enterprise environments.
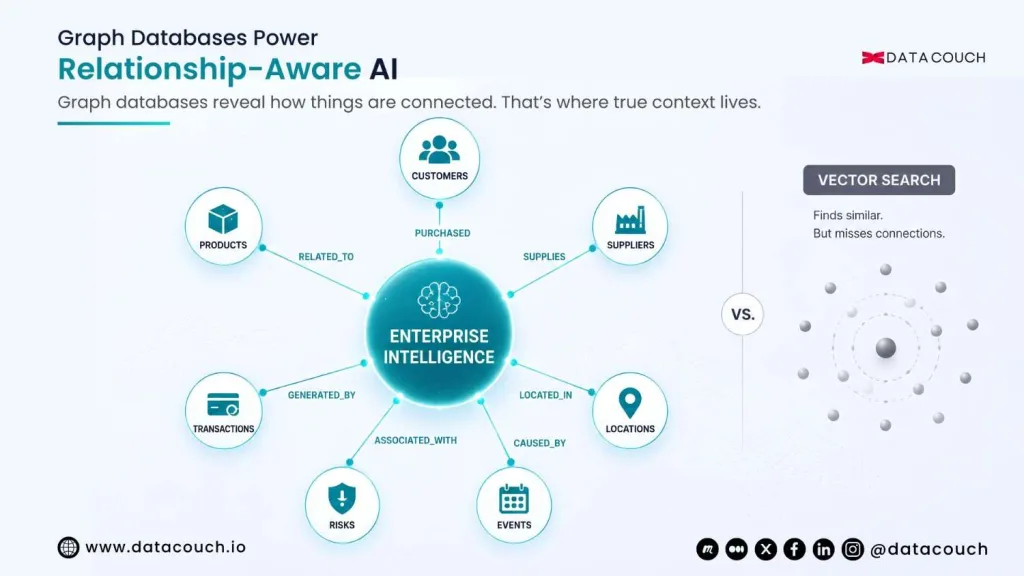
The Problem Vector Search Cannot Solve
Similarity Is Not the Same as Understanding
A vector database excels at one thing: finding text or data that is semantically similar to a query. Ask it which documents mention customer churn, and it will return the most similar passages. Ask it why a specific customer churned, given their purchase history, support ticket pattern, contract renewal timing, and the sales team’s engagement record, and it returns passages about churn without any awareness of the relationships between those entities.
Enterprise AI questions are almost always relationship questions. Which suppliers are connected to the components failing in our highest-margin product line? Which customers who reduced their spend this quarter were also touched by the same support team? Which transactions share characteristics with the 12 confirmed fraud cases from last quarter? None of these questions can be answered by finding similar text. They require traversing relationships across connected data.
Gartner’s 2025 Hype Cycle for Generative AI places knowledge graphs in the Slope of Enlightenment, signalling growing maturity and mainstream enterprise adoption. Gartner also reports that up to 50% of its AI-related client inquiries involve discussion of graph technology.
What Neo4j Actually Does in an Enterprise AI Architecture
The World's Leading Graph Database, Used by 84% of Fortune 100 Companies
Neo4j is the world’s leading graph database platform, used by 84% of Fortune 100 companies and 58% of the Fortune 500, including organisations such as Daimler, Dun and Bradstreet, EY, IBM, Merck, NASA, UBS, and Walmart. Gartner recognised Neo4j as a Visionary in its 2024 Magic Quadrant for Cloud Database Management Systems for the second consecutive year. Forrester ranked Neo4j as a Strong Performer in its Vector Databases Wave, reflecting the company’s expanding role in the AI retrieval stack.
The core architectural role Neo4j plays in an enterprise AI system is the knowledge layer: the representation of entities and the relationships between them that gives AI the context to reason accurately about complex, connected questions.
The Five Enterprise Use Cases Where Graph Databases Outperform Everything Else
| Use Case | Why Graph Wins | What Flat Databases Miss |
|---|---|---|
| Fraud detection and financial crime | Graph queries traverse transaction networks in real time, identifying rings of connected accounts, shared devices, and unusual relationship patterns across millions of entities | Relational databases can join tables, but cannot efficiently traverse multi-hop relationship networks at the speed fraud detection requires |
| Knowledge graph for enterprise AI | Connects products, customers, suppliers, risks, events, and internal documents into a queryable relationship map that LLMs use as authoritative context | Vector search finds similar text but cannot answer questions that require traversing relationships: why did this customer churn, what caused this supply chain failure |
| Supply chain risk intelligence | Maps supplier relationships, component dependencies, geographic concentrations, and contractual obligations as a connected graph with real-time event overlay | Spreadsheet and relational database supply chain models cannot represent multi-tier supplier relationships or propagate risk signals through the network |
| Recommendation and personalisation | Combines behavioural signals, product relationships, and customer network effects into contextually rich recommendations that improve with graph depth | Collaborative filtering approaches miss relationship context: that two products are used together by experts versus together by beginners is a relationship signal that flat data cannot capture |
| IT and security operations | Maps infrastructure dependencies, access relationships, and threat propagation paths across connected systems, enabling faster incident response and blast radius assessment | Alert correlation tools see events in isolation; the graph sees which systems are connected and how a compromise in one propagates to others. |
DataCouch is a certified Neo4j implementation partner.
We build knowledge graphs that make your enterprise AI reliable.
GraphRAG vs. Vector RAG: The Technical Difference That Matters for Enterprise AI
How Vector RAG Works and Where It Falls Short
Standard Retrieval-Augmented Generation converts your documents into numerical vector embeddings and stores them in a vector database. When a user asks a question, the system finds the most similar vectors and passes the corresponding text chunks to the language model. The model generates an answer based on those chunks.
This works well when the answer exists explicitly in a single document or a small set of similar documents. It breaks down when the answer requires synthesising information from multiple connected sources, understanding relationships between entities, or reasoning about how events propagate through a network.
How GraphRAG Works and Why It Changes What Is Possible
GraphRAG retrieves not just similar text but also entities and the relationships between them. When a user asks a complex question, the graph traversal identifies the relevant entities and traces the relationships that connect them. The language model receives not just text chunks but structured context: this customer is connected to this account manager, who is also managing three other accounts that declined this quarter, all of which were touched by this support team in the 90 days prior to decline.
Gartner noted the importance of GraphRAG in its Hype Cycle for AI in Software Engineering: “RAG techniques in an enterprise context suffer from problems related to the veracity and completeness of responses caused by limitations in the accuracy of retrieval.” Graph-enhanced retrieval directly addresses this limitation by providing relationship context that pure vector similarity cannot capture. The result is AI answers that are more accurate, more complete, and grounded in the actual relationships in your enterprise data rather than the textual similarity of your documents.
How DataCouch Implements Neo4j for Enterprise AI
DataCouch is a certified Neo4j implementation partner. Our engagements follow a structured four-stage approach that moves from data model design through production deployment, with a training component at every stage.
Step 1: Graph Data Model Design
Every successful Neo4j deployment starts with a domain-specific graph data model: defining the entities that exist in your data, the relationships that connect them, and the properties that describe both. A well-designed graph model is the difference between a knowledge graph that answers complex questions correctly and one that answers simple questions slowly. DataCouch’s consulting team designs graph models specific to your industry domain and query requirements.
Step 2: Data Integration and Pipeline Design
Neo4j works best when it stays current with your enterprise data. This means designing integration pipelines that move relevant data from your operational systems, data warehouse, and document stores into the graph continuously. For real-time fraud detection and supply chain risk, DataCouch uses Confluent or Redpanda for event streaming into Neo4j, ensuring the graph reflects the current state rather than yesterday’s batch load.
Step 3: GraphRAG Architecture and LLM Integration
Connecting Neo4j to your enterprise AI applications requires designing the retrieval layer: how user questions are translated into graph queries, how retrieved entities and relationships are formatted as context for the language model, and how the system combines vector search for unstructured content with graph traversal for structured relationships. DataCouch designs and implements this hybrid retrieval architecture for production AI applications.
Step 4: Team Training and Capability Building
Neo4j uses Cypher, its own query language for graph traversal. DataCouch delivers certified Neo4j training for data engineers, data scientists, and AI developers who will build and maintain the knowledge graph. This training covers graph data modelling, Cypher query writing, graph algorithm application, and the specific patterns used in GraphRAG implementations.
We specialise in custom AI programs and globally recognised certification training at scale.
Key Takeaways
- Vector search finds similarity. Graph databases find relationships. Enterprise AI questions are almost always relationship questions, which is why 95% of GenAI pilots that rely only on vector search fail to reach production.
- Knowledge graphs are the context layer that makes LLMs reliable in enterprise environments. Gartner states directly that without knowledge graphs, AI systems cannot avoid hallucinations in complex enterprise queries.
- Neo4j is used by 84% of Fortune 100 companies. It is not an emerging technology. It is established enterprise infrastructure that most AI teams have not yet connected to their AI strategy.
- GraphRAG retrieves entities and relationships, not just similar text. This gives language models the structural context to answer complex, connected questions that pure vector retrieval cannot address.
- The top enterprise use cases for graph AI include fraud detection, enterprise knowledge graphs for AI assistants, supply chain risk, recommendation systems, and IT and security operations.
- Graph technology is entering mainstream adoption per Gartner’s 2025 Hype Cycle. The organisations building graph foundations for their AI now will have context quality advantages that cannot be replicated by adding more vector embeddings later.
Here is the question worth asking about your enterprise AI strategy: when your AI assistant answers a complex question about your business, does it understand the relationships between the entities involved, or is it finding the most similar sentence in your document library?
The difference between those two answers is the difference between an AI that helps and one that confidently misleads.




