
Kafka vs. Redpanda in 2026: The Enterprise Architect's Decision Matrix

Why This Comparison Matters More in 2026 Than Ever Before
Here’s the surprising truth: most Kafka vs. Redpanda articles circulating online right now are already out of date. They were written before March 18, 2025, the day Apache Kafka 4.0 shipped and permanently changed this conversation.
This is not a minor update. Kafka 4.0 removed ZooKeeper entirely, which was Redpanda’s single biggest argument for years. So if you’re a manager, CTO, CFO, or team lead trying to make a platform decision in 2026, reading old comparison articles is actively misleading you.
The good news? We’ve done the digging. This article gives you a fresh, honest, and practical breakdown of both platforms based on what is actually true right now.
And the stakes are real. According to market research from MarketIntelo, the global Kafka streaming market was valued at $1.8 billion in 2024 and is projected to hit $7.9 billion by 2033, growing at 17.8% CAGR. If your organization has not made a deliberate data streaming decision, it is already behind.
What Kafka 4.0 Changed (And Why Most Comparisons Missed It)
For years, Redpanda’s pitch was simple: “We don’t need ZooKeeper, and Kafka does.” That pitch is no longer valid.
Kafka 4.0, released in March 2025, completed the full removal of ZooKeeper. The new metadata system, called KRaft, is now the only way to run Kafka. What does this mean in practice?
- Kafka now supports up to 1.9 million partitions, compared to the previous ceiling of a few hundred thousand.
- Topic creation and partition rebalancing are now O(1) operations, meaning the cluster does not slow down as it grows.
- One fintech team reported cutting cluster setup time by roughly 40% after removing ZooKeeper from their workflow, according to Java Code Geeks.
- A SaaS provider reduced infrastructure costs by around 20% by retiring dedicated ZooKeeper nodes.
Kafka 4.0 also introduces KIP-848, a new consumer group protocol that eliminates the “stop the world” rebalance problem that plagued large Kafka deployments. And KIP-932 adds early access to Queue semantics, so Kafka can now handle traditional point-to-point messaging patterns without a separate system.
The Migration Warning Nobody Is Talking About
If you’re running Kafka right now with ZooKeeper, you cannot upgrade directly to Kafka 4.0. You must first migrate to KRaft within Kafka 3.x, then upgrade to 4.0. Teams that delay this migration are accumulating technical debt. The official Apache Kafka upgrade documentation is clear on this: ZooKeeper mode is completely gone.
Is your team ready for the KRaft migration?
DataCouch's Apache Kafka Administration by Confluent course covers cluster building, KRaft operations, security hardening, and real-world upgrade strategies, taught by instructors who have trained over 300,000 professionals at companies like Adobe, Google, and Walmart.
Architecture: What's Actually Different Under the Hood
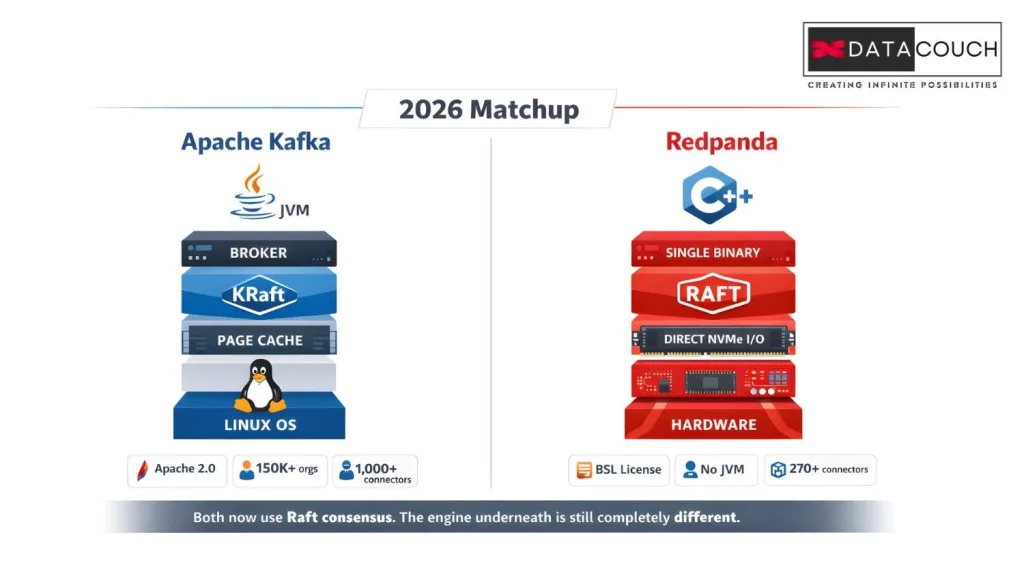
Both platforms handle real-time data streaming. Both use a distributed log model with topics and partitions. But the engine underneath is completely different, and those differences determine which one fits your workload.
| Feature | Apache Kafka 4.0 | Redpanda |
|---|---|---|
| Language | Java / Scala (JVM) | C++ (No JVM) |
| ZooKeeper | Removed in v4.0 (KRaft) | Never needed it |
| Consensus Protocol | KRaft (Raft-based, new) | Raft-based (5+ years in prod) |
| Storage I/O | Linux page cache | Direct NVMe I/O (self-managed) |
| Deployment | Multi-binary cluster | Single binary |
| ARM Hardware Support | Poor (Java GC issues on ARM) | Excellent (runs faster on ARM) |
| Garbage Collection | Yes (JVM GC pauses) | None (C++ manages memory) |
The JVM Problem Is Still Real
Kafka 4.0 still runs on the Java Virtual Machine. That means garbage collection pauses are still a thing. In most enterprise workloads, these pauses are manageable. But in latency-sensitive environments, like financial trading or real-time fraud detection, a GC pause at the wrong moment can cause visible SLA violations.
Redpanda completely avoids this. It’s written in C++ and manages its own memory. There is no JVM, no GC tuning, no heap sizing. Engineers who have migrated often describe it as “removing a temperamental animal from the stack,” as documented in real-world migration accounts on DEV Community.
The Page Cache Debate Nobody Explains
Here’s something most comparison articles skip entirely. Kafka’s storage relies on the Linux page cache. This design is why Kafka can achieve extremely high throughput across a wide variety of workloads. The page cache is an elegant solution for diverse data patterns.
But the page cache is also unpredictable. It can spike latency at exactly the wrong moment, particularly under sustained high-throughput conditions. Independent testing by Confluent principal technologist Jack Vanlightly, cited across independent benchmarking by Confluent principal technologist Jack Vanlightly, found that Kafka’s page cache design is both its greatest strength and its source of tail latency instability.
Redpanda bypasses the page cache entirely and manages its own I/O. The result is more predictable latency, but different trade-offs under sustained heavy load, which we cover in the next section.
Performance: Reading Benchmarks Like an Architect

What most people don’t realize is that both vendors publish benchmarks that favor their own platform. Here is what the independent data actually shows, so you can make a decision that holds up in production.
| Metric | Apache Kafka 4.0 | Redpanda |
|---|---|---|
| P99 Latency (optimized) | 15 to 25ms | 8 to 15ms |
| P99.99 Tail Latency | Baseline | Up to 10x faster (vendor claim) |
| Nodes for 1 GB/s workload | 9+ instances | 3 instances |
| ARM Hardware Performance | Poor (Java GC limitations) | Strong (faster on Graviton) |
| 12-Hour Sustained Load | Stable across diverse workloads | Performance can degrade near retention limit |
| Large Backlog Drain | Handles well under constant 1 GB/s | Struggles under sustained heavy load |
| 2024 Latency Update | KRaft reduces partition recovery time | v24.1 claims 98% lower latency on heavy loads |
Redpanda's Numbers Are Real, But Conditional
Redpanda’s benchmarking, as reported by The New Stack, confirmed 10x faster tail latencies than Kafka at p99.99 after over 200 hours of testing. Under a 1 GB/s workload, Redpanda required 3 server instances. Kafka required 9 and still showed worse performance.
But here is the part that rarely makes it into vendor marketing. Independent third-party benchmarks on identical hardware found that Redpanda’s performance degraded significantly after 12 hours under sustained load, and that Kafka could drain large backlogs at 800 MB/s to 1 GB/s that Redpanda simply could not handle. Redpanda’s performance advantages are real, but they are workload-specific, not universal.
The ARM Hardware Variable Your Cloud Budget Cares About
This is one of the most overlooked cost levers in the entire debate. Redpanda runs faster on ARM-based hardware, including AWS Graviton instances. Kafka, running on Java, has documented performance degradation on ARM due to how Java’s crypto providers handle ARM architecture, as noted in The New Stack’s analysis of Redpanda vs. Kafka. If your cloud strategy involves Graviton instances for cost savings, this single factor can meaningfully shift the infrastructure cost comparison.
The gap between benchmark results and production reality almost always comes down to how well your team can tune the cluster. Explore DataCouch's full Confluent training catalogue, covering developer skills, Kafka Streams, ksqlDB, and cluster administration, to build the hands-on expertise your team needs.
TCO: The Number Your CFO Actually Wants to See
Most TCO comparisons just look at server count. That misses the real cost drivers. Here is the full picture.
Redpanda's Claimed Savings
Redpanda claims to be 3 to 6 times more cost-effective than equivalent Kafka infrastructure. Their tiered storage feature reportedly delivers savings of $70,000 to $1.2 million, depending on workload size, as documented on The New Stack. One enterprise customer reported saving 30% on storage costs while handling 14.5 GB/second of throughput.
Kafka 4.0 Closed One Major Cost Gap
The removal of ZooKeeper in Kafka 4.0 eliminates what was previously a significant hidden cost: dedicated ZooKeeper nodes, separate monitoring, and the specialized expertise needed to operate a two-system architecture. That cost advantage for Redpanda has been partially closed.
The Costs Nobody Puts in Their TCO Calculator
- JVM tuning expertise: Kafka requires ongoing JVM heap sizing, GC tuning, and incident response when GC pauses cause latency spikes. This is either a recurring ops cost or a training investment.
- Redpanda Enterprise license: Features like Tiered Storage, Remote Read Replicas, SSO, and RBAC all require a paid commercial license. The community edition under BSL is free, but enterprise-grade operations likely require paid features.
- Talent market premium: Kafka engineers are far more available in the job market. According to Enlyft industry data, over 49,700 companies use Kafka. That means more engineers, more training options, and lower hiring costs.
Licensing: The Legal Risk Most Teams Discover Too Late
This is the section that most comparison articles skip entirely. It matters a lot if you’re in procurement, legal, or strategic planning.
Apache Kafka: Apache 2.0, Zero Friction
Kafka is licensed under Apache 2.0. Any organization can use it, modify it, build on it, and distribute it. There is no legal review required. No commercial restrictions. This is why it is trusted by over 150,000 organizations globally, including more than 80% of Fortune 100 companies.
Redpanda's BSL License: What It Actually Restricts
Redpanda’s Community Edition uses the Business Source License (BSL). You can use it freely for internal applications. But the BSL explicitly prohibits offering Redpanda as a commercial streaming or queuing service to third parties. The BSL code does convert to Apache 2.0 after four years, but only for that specific code version, not for new releases.
Who does this impact most?
- SaaS platforms and managed service providers who want to offer streaming as a feature to their customers
- Enterprises in heavily regulated industries whose legal teams flag non-Apache licenses during procurement
- Organizations building internal data platforms that will eventually be productized or resold
Ecosystem and Talent: Kafka's Decade-Long Moat
Kafka has a 14-year head start. That gap does not close with better benchmarks.
- Connectors: Kafka has 1,000+ Kafka Connect connectors. Redpanda has 270+ connectors and is growing.
- Stream processing: Kafka Streams and Apache Flink integrations with Kafka are deeply mature. Redpanda’s equivalent, Redpanda Connect (formerly Benthos), is capable but newer.
- Observability tooling: Years of production deployments have produced a rich ecosystem of monitoring tools, runbooks, and community knowledge around Kafka.
- Talent availability: With 49,700+ companies running Kafka according to Enlyft, hiring Kafka engineers is straightforward. Redpanda expertise is a much smaller and more competitive talent pool.
For engineering directors, this is a practical constraint, not just a theoretical one. Corporate training for Kafka is far more mature, widely available, and backed by official certification paths through Confluent.
Recognized three consecutive years as Confluent's Global Education Delivery Partner of the Year, DataCouch offers the complete official Confluent Kafka training catalogue. From developer skills and ksqlDB to cluster administration and Kafka Streams, there is a structured upskilling path for every role on your team, whether you are onboarding new hires or deepening your existing team's expertise.
The 2026 Angle Nobody Is Writing About: AI and LLM Pipelines
Here is where this comparison gets genuinely interesting for organizations building AI infrastructure right now. Both platforms are positioning themselves as the backbone for AI data pipelines, but in very different ways.
| AI Use Case | Winner | Why |
|---|---|---|
| Real-time RAG pipelines | Redpanda | Sub-10ms latency, simpler single-binary stack |
| LLM training data pipelines | Kafka | Volume, durability, deep Spark integration |
| AI feature stores | Kafka + Flink | Stateful stream processing maturity |
| Edge AI inference | Redpanda | ARM efficiency, single binary deploys fast |
| Enterprise AI at Fortune 500 scale | Kafka | Proven at 150,000+ org deployments, ecosystem depth |
Redpanda recently acquired Oxla, a SQL query engine, specifically to add real-time analytics and ad-hoc querying to its platform. This is a direct move to compete with Kafka’s growing AI infrastructure role. Meanwhile, Kafka is becoming the backbone for AI data pipelines at scale, with integration with AI accelerating across enterprise deployments in 2025.
Real Migration Stories: What Engineers Actually Experience
The marketing from both sides makes migration sound either terrifying or trivially easy. Neither is fully accurate. Here is what real engineers found.
The Surprisingly Smooth Part
Because Redpanda is API-compatible with Kafka, application-level changes are minimal. Multiple engineering teams have described starting the migration by simply pointing a single producer at the Redpanda broker address with no code changes. The service behaved identically, as documented in a detailed December 2025 engineering account on Medium.
Redpanda broker restarts happen in under one second. For teams accustomed to Kafka restarts measured in minutes, this is genuinely jarring at first.
The Parts That Create Real Friction
- Older Kafka clients using deprecated protocol versions may not be compatible out of the box
- Existing monitoring dashboards built for Kafka metrics do not map directly to Redpanda’s metric output
- Internal tooling often has Kafka-specific assumptions baked in that require reworking
- Data migration rate: approximately 85 terabytes per day on a single 10-gigabit link using MirrorMaker2, per Redpanda’s official migration guide
When You Should NOT Migrate
- Your stack is deeply integrated with Kafka Streams or Apache Flink, where Kafka’s native tooling is far more mature
- You operate in a regulated industry with existing Kafka vendor SLAs and compliance certifications in place
- Your team does not yet have solid Kafka production expertise, and migration risk compounds with operational immaturity
- Your workload involves sustained high-partition loads at 800 MB/s or above, where Redpanda’s backlog draining instability has been documented
Before committing to a migration, it is worth asking whether your Kafka cluster is already optimized. Many teams move away from Kafka before they have properly tuned it, only to find similar challenges on the other side. DataCouch's Apache Kafka Administration by Confluent gives ops teams the hands-on skills to benchmark, tune, secure, and scale Kafka clusters, so the decision to stay or migrate is informed rather than reactive.
The Decision Matrix: Which Platform Fits Your Organization
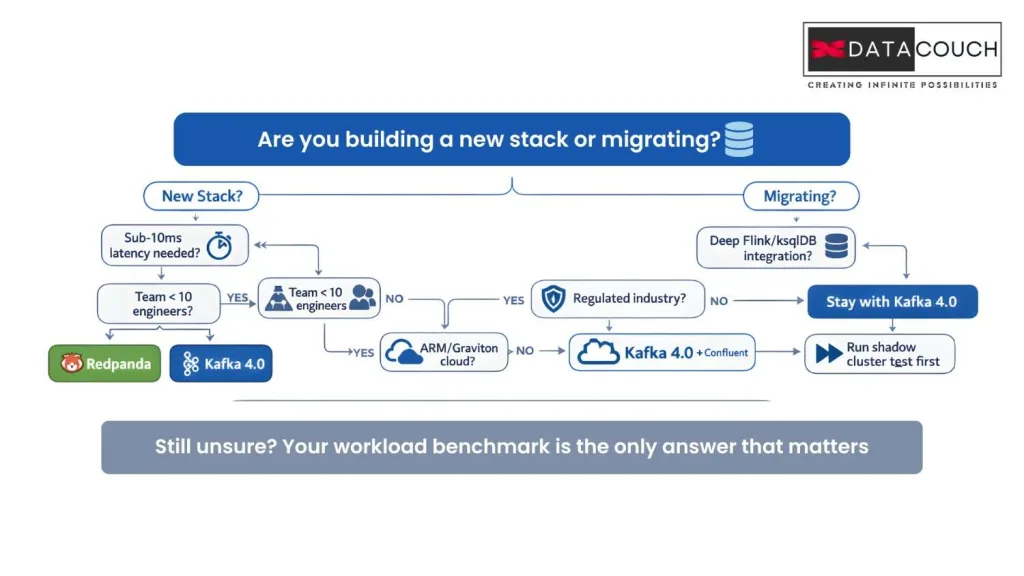
Here is the straightforward breakdown for enterprise architects and business leaders making this decision right now.
| Your Situation | Go With Kafka 4.0 | Go With Redpanda |
|---|---|---|
| Latency SLA | Under 25ms is fine | Sub-10ms p99 is mandatory |
| Team Expertise | Existing Kafka ops team in place | Greenfield or lean DevOps team |
| Workload Pattern | Sustained high-throughput, large partition counts | Bursty, latency-sensitive workloads |
| Hardware | x86 cloud VMs, managed services | ARM / Graviton, NVMe-heavy bare metal |
| Ecosystem Depth | Need Flink, Spark, ksqlDB, 1,000+ connectors | Lighter stack, 270+ connectors sufficient |
| AI / LLM Pipelines | Large-scale feature stores, training data pipelines | Real-time RAG, edge AI inference |
| Licensing & Legal | Apache 2.0, zero procurement friction | BSL license, legal review needed if you resell |
| Regulated Industry | Preferred (mature compliance tooling) | Evaluate on a case-by-case basis |
| Managed Cloud Service | Confluent Cloud, AWS MSK, GCP Managed Kafka | Redpanda Cloud (BYOC available) |
The Five Enterprise Personas
The Cost-Pressed CTO: If your workload fits Redpanda’s strengths, the 3 to 6x TCO reduction is real. Validate with your specific workload before committing.
The Risk-Averse Enterprise Architect: Kafka 4.0 plus Confluent Cloud is the lower-risk choice. Apache 2.0 licensing, mature compliance tooling, and a decade of production hardening.
The AI/ML Platform Engineer: Depends entirely on pipeline type. Real-time RAG leans Redpanda. Large-scale feature engineering leans Kafka with Flink.
The Greenfield Startup Founder: Redpanda wins on operational simplicity, faster time to production, and lower engineering overhead for a small team.
The Regulated Industry CISO: Apache 2.0, the scale of Kafka’s ecosystem, and the depth of existing compliance tooling make Kafka 4.0 the default choice.
Key Takeaways
Kafka 4.0 closed the operational complexity gap that Redpanda was originally built to exploit. ZooKeeper is gone. KRaft is here. The “Kafka is hard to run” narrative is now much less valid than it was 18 months ago.
But Redpanda still leads on raw latency, hardware efficiency especially on ARM, single-binary simplicity, and developer experience. For specific workloads, those advantages are real and material.
The most sophisticated architectures in 2026 may not be choosing one platform. They may be running both: Kafka as the enterprise backbone for ecosystem-heavy workloads, and Redpanda for latency-critical edge cases.
Whichever direction you go, the platform only performs as well as the team operating it. A Kafka cluster with poor tuning will underperform Redpanda on every metric. A well-tuned Kafka 4.0 cluster with a skilled ops team is a different beast entirely. The investment in upskilling your engineering team is not optional. It is the variable that determines whether you capture the value on the whiteboard or struggle to replicate it in production.
Ready to build or sharpen your team's Kafka expertise?
Explore the full Confluent training catalogue at DataCouch, from developer skills and ksqlDB to the Apache Kafka Administration by Confluent course built for the engineers responsible for keeping your streaming infrastructure alive and performant.
A Question Worth Sitting With
Your organization’s data streaming decision shapes your real-time capabilities for the next five to seven years. Given what you now know about Kafka 4.0’s changes and Redpanda’s genuine strengths, is your team currently equipped to make, execute, and operate that decision at production scale? If not, what is the one upskilling investment that would change that answer?
Sources
MarketIntelo: Kafka Streaming for Warehouse Data Market Research 2033
Apache Kafka 4.0 Official Upgrade Documentation
Java Code Geeks: Kafka 4.0 and KRaft, The End of ZooKeeper
The New Stack: Data Streaming, When Is Redpanda Better Than Apache Kafka
Redpanda: Performance Benchmark vs Apache Kafka
Kai Waehner: Apache Kafka 4.0 Business Case for Enterprise
Redpanda Licensing Overview (Official Docs)
Enlyft: Apache Kafka Market Share and Industry Data
DEV Community: We Migrated From Kafka to Redpanda, What Actually Happened
Medium: We Replaced Kafka With Redpanda in Production (December 2025)



