
Zero-Copy Data: Why Starburst is the Missing Layer for Your AI Stack
Picture this. Your company just spent six months building an AI model to predict customer churn. The data science team is excited. Leadership is eager to see results. But then someone asks a simple question: where is the training data coming from?
The answer? Twelve different sources. Three cloud platforms. Two on-premises databases. And a Salesforce instance nobody wants to touch. The data engineering team estimates 9 to 12 weeks just to build the pipelines. Sound familiar?
Here is the uncomfortable truth most AI conversations skip over. The model is rarely the problem. The data layer is. According to RAND Corporation research, over 80% of AI projects fail to reach production. That is twice the failure rate of regular IT projects. And the Informatica CDO Insights 2025 survey found that 43% of organizations point to data quality and readiness as their top obstacle to AI success.
Zero-copy data access is the ability to query and use data in its original location without copying, moving, or duplicating it across systems. Starburst, built on the open-source Trino engine, provides this missing federation layer for enterprise AI stacks.
The Real Reason Your AI Projects Keep Stalling
Most companies today run their data across multiple clouds, on-premises servers, and dozens of SaaS applications. The MuleSoft 2025 Connectivity Benchmark reveals that organizations average around 897 apps, but only 28% of those apps are connected. Even worse, 95% of IT leaders say these integration gaps directly block AI adoption.
The traditional fix? Build ETL pipelines. Extract data from every source. Transform it. Load it into a centralized warehouse. Then pray nothing breaks before your model finishes training.
This approach worked well enough for BI dashboards. But AI is a different beast. Models need fresh data from across the entire business. They need it governed. They need it fast. And they need access to structured, semi-structured, and unstructured data all at once.
The Hidden Tax Nobody Talks About
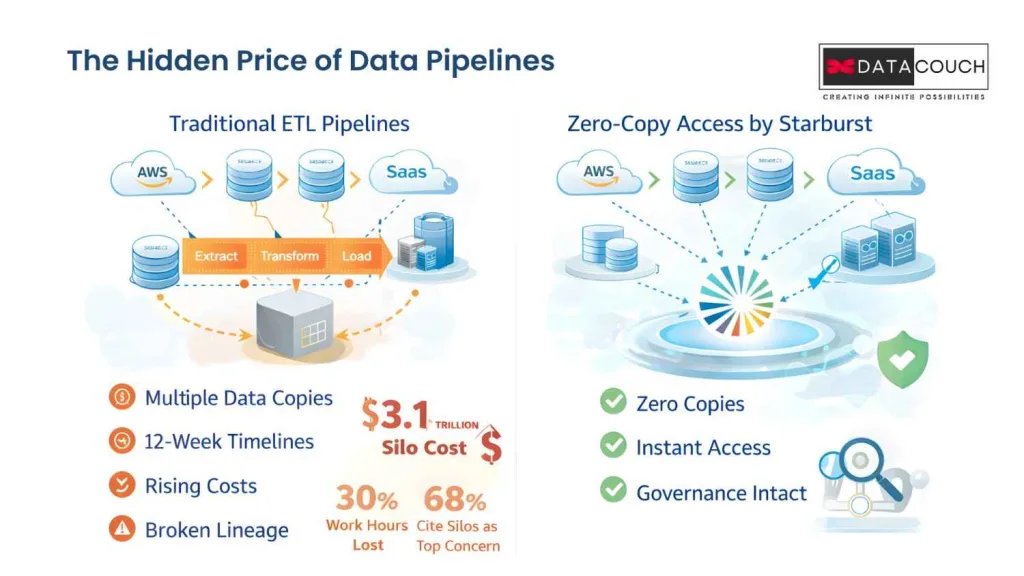
What most people do not realize is that data movement itself is the biggest hidden cost in AI. IDC research shows that data silos cost the global economy $3.1 trillion every year. A 2024 Infoverity report found that employees lose 30% of their weekly work hours just chasing data trapped in disconnected systems.
And here is the part that really stings. The DATAVERSITY 2024 Trends in Data Management survey found that 68% of respondents now cite data silos as their top concern, up 7% from the year before. The problem is getting worse, not better.
Every copy of your data costs money to store, sync, and govern. Every pipeline introduces latency. Every transformation risks losing lineage. For AI workloads that depend on complete and current data, this traditional approach is simply too slow and too expensive.
What Starburst Actually Does (and Why It Matters for AI)
Starburst is a data platform built on Trino, an open-source distributed SQL query engine originally created at Facebook. Instead of moving data into one place, Starburst lets you query data wherever it already lives. Across clouds. Across on-premises databases. Across 50 or more different data sources. All through a single SQL interface.
It comes in two flavors. Starburst Galaxy is the fully managed cloud version. Starburst Enterprise handles on-premises and hybrid deployments. Both are built on Apache Iceberg, the open table format that has rapidly become the standard for modern data lakes.
Here Is What Makes Starburst Different from a Regular Query Engine
Most articles describe Starburst as “just a Trino distribution.” That was true three years ago. It is not true anymore. In 2025, Starburst released a set of AI-specific capabilities that reposition it as critical infrastructure for enterprise AI.
- AI Workflows that transform unstructured data (documents, images, logs) into vector embeddings without separate tooling.
- A built-in AI Agent that lets users query data using natural language and generates SQL behind the scenes.
- An MCP (Model Context Protocol) server and Agent API that allow multiple AI agents to discover, query, and act on governed data.
- Open vector store access through Iceberg, PGVector, and Elasticsearch, giving retrieval-augmented generation (RAG) workflows access to both structured and unstructured data.
- AI observability dashboards that track LLM usage, set cost guardrails, and monitor agent activity.
This is not a cosmetic AI wrapper. Starburst is building a complete data access and governance layer designed specifically for the age of autonomous AI agents.
Want your team to master Starburst hands-on? Explore DataCouch's official Starburst training courses and get your data engineers production-ready on federated queries, Iceberg, and Galaxy.
The Model-to-Data Shift: Why This Changes Everything
For the last decade, the default approach has been “data-to-model.” You move all your data into one platform, clean it up, and then point your models at it. Databricks, Snowflake, and every cloud warehouse is built on this idea.
Starburst flips this around. Their approach is “model-to-data.” Instead of moving terabytes of data to where your AI model sits, you bring the model (or agent) to the data. The data stays where it is. Governed. Fresh. No copies.
Matt Fuller, VP of AI/ML Products at Starburst, put it clearly in a BigDATAwire interview: the goal is to minimize data movement and bring compute to the data, not the other way around.
This matters because Gartner predicts that through 2026, organizations will abandon 60% of AI projects that lack AI-ready data. The model-to-data approach solves this by eliminating the need for massive data migrations before you can even start an AI project.
Starburst vs. the Competition: An Honest Comparison
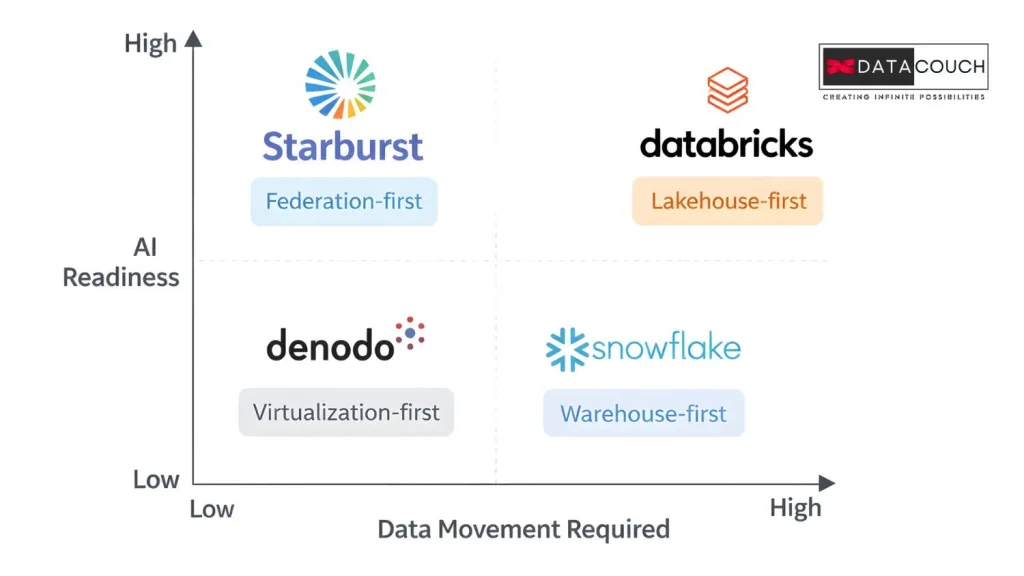
No platform does everything. Here is a straightforward look at where Starburst wins and where alternatives make more sense.
| Feature | Starburst | Databricks | Snowflake |
|---|---|---|---|
| Core Approach | Federation-first: query data where it lives | Lakehouse-first: centralize data in Delta Lake | Warehouse-first: ingest data into Snowflake cloud |
| Data Movement | Zero-copy, no replication needed | Requires ETL/ingestion for best performance | Requires ingestion into Snowflake platform |
| AI Strategy | Model-to-data, Lakeside AI, MCP server for agents | Mosaic AI, agent framework, ML-native | Cortex AI, in-platform ML, Snowflake Intelligence |
| Open Source Base | Trino (fully open) | Apache Spark | Proprietary |
| On-Prem Support | Full on-prem and hybrid | Limited on-prem options | Cloud-only |
| Table Format | Iceberg-native, new catalog replacing Hive | Delta Lake native; Iceberg via Tabular acquisition | Iceberg support added; proprietary Open Catalog |
| Best For | Distributed, multi-source, regulated industries | AI/ML-heavy teams, Spark-native orgs | SQL analytics, managed simplicity, structured data |
| Lock-in Risk | Low (open-source Trino + Iceberg) | Moderate (Spark ecosystem dependency) | Higher (proprietary compute, data gravity) |
The Surprising Truth: Starburst Often Works With These Platforms, Not Against Them
In real enterprise deployments, a common pattern is using Snowflake or Databricks as the storage foundation and layering Starburst on top for federation across sources that sit outside the warehouse. A 2025 data mesh guide describes this as the “Storage + Virtualization” architecture, where Starburst provides a unified query interface while each domain keeps its own storage.
This is a critical nuance that competitor articles almost always miss. Starburst is not necessarily a replacement for your data warehouse. It is the connective tissue that makes your entire data ecosystem accessible to AI.
Not sure where Starburst fits in your current stack?
Talk to DataCouch's Starburst consulting team for a personalized architecture assessment and implementation roadmap.
Why Agentic AI Makes Starburst Essential (Not Just Nice to Have)
The Deloitte State of AI 2026 report found that agentic AI usage is set to rise sharply in the next two years. But only 1 in 5 companies has a mature governance model for autonomous AI agents.
This gap is where Starburst becomes essential. AI agents do not browse dashboards. They need programmatic, governed, real-time access to data across the full enterprise. Not just whatever sits in one warehouse.
Starburst’s new MCP server and Agent API mean that AI agents can discover relevant data, generate queries, and return results, all within a governed framework that tracks every interaction. For regulated industries like healthcare, finance, and manufacturing, this is not optional. It is a requirement.
The Bold Thesis Most People Are Ignoring
Starburst published a provocative argument in 2025: traditional SaaS applications (Salesforce, SAP, ServiceNow) will face disruption because AI agents do not need traditional user interfaces. Agents communicate through MCP, A2A, and API protocols, not GUIs.
If an organization controls its own data layer through a platform like Starburst (zero-copy, governed, cross-cloud), it can bypass SaaS vendor lock-in entirely. The data layer becomes the new competitive battleground. It is worth noting that Salesforce’s Data Cloud, SAP’s partnership with Databricks, and ServiceNow’s AI investments are all responses to this exact threat.
Apache Iceberg: The Open Foundation Powering Starburst's AI Future
You cannot talk about Starburst without talking about Apache Iceberg. Originally developed at Netflix, Iceberg has become the open table format of choice for modern data lakes.
A 2026 practitioner survey from DataLakehouseHub found that 96.4% of respondents use Spark with Iceberg and 60.7% use open-source Trino (Starburst’s engine). The survey confirms that Iceberg is now structurally multi-engine, meaning it works across different platforms without vendor lock-in.
Here is why Iceberg matters specifically for AI workloads.
- Time travel: query data as it existed at any point in the past, perfect for reproducible training datasets.
- ACID transactions: safe concurrent reads and writes, so model training does not corrupt production data.
- Schema evolution: add, rename, or drop columns without rewriting entire tables.
- Hidden partitioning: automatic performance optimization without manual partition management.
In 2025, Starburst replaced the aging Hive metastore with a new Iceberg-native catalog and launched fully managed Iceberg pipelines with automated compaction and streaming ingestion. This gives teams a complete, AI-ready data management layer without building custom infrastructure.
Building on Starburst and Iceberg? Upskilling your team is the fastest path to ROI. Check out DataCouch's Starburst certification courses to get hands-on with Galaxy, Trino, and Iceberg table formats.
Real-World Architecture: Where Starburst Fits in the AI Stack
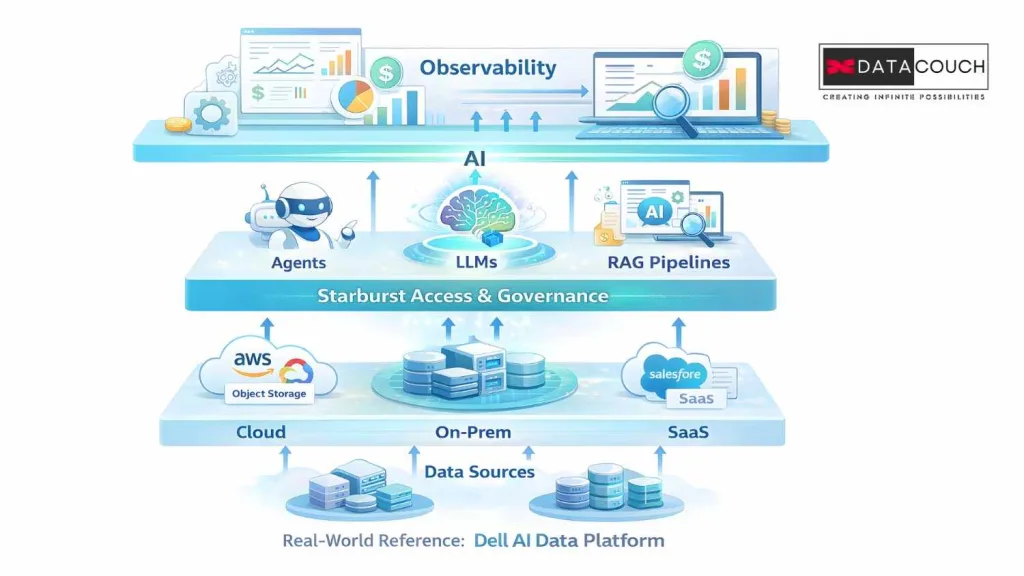
In late 2025, Dell announced its AI Data Platform built on four pillars: PowerScale, ObjectScale, Elastic, and Starburst. This is a production-grade reference architecture that positions Starburst as a core component of enterprise AI infrastructure alongside Nvidia GPU integration.
A practical AI stack with Starburst looks like this.
- Data layer: object storage (S3, GCS, ADLS) as the system of record, plus existing databases, SaaS apps, and on-prem systems.
- Access and governance layer: Starburst provides unified, federated access with built-in RBAC, ABAC, lineage tracking, and compliance controls (GDPR, Schrems II).
- AI layer: LLMs and agents (OpenAI, Anthropic Claude, open-source models) query data through Starburst’s MCP server and Agent API.
- Observability layer: Starburst dashboards monitor AI usage, enforce guardrails, and track costs.
The key advantage? No data moves. The AI models come to the data. Governance stays intact. Compliance stays clean. And you do not spend 12 weeks building pipelines before your first experiment.
What This Means for Your Team (and How to Get Started)
The Stanford HAI AI Index 2025 reported that 78% of organizations now use AI in at least one business function. But S&P Global’s 2025 survey found that 42% of companies abandoned most of their AI initiatives this year. The gap between adoption and successful deployment is enormous.
Closing that gap starts with the data layer. If your team cannot access governed, complete data across your entire enterprise without months of pipeline work, your AI projects will keep stalling.
Upskilling your data engineering and platform teams on technologies like Starburst, Trino, and Apache Iceberg is one of the highest-ROI investments you can make right now. IDC research found that companies with strong data integration achieve 10.3x ROI from AI, compared to just 3.7x for those with weak connectivity.
Stop Moving Data. Start Moving Forward.
The numbers tell a clear story. 80% of AI projects fail. 43% cite data readiness as the top barrier. Data silos cost the global economy $3.1 trillion a year. And the average enterprise runs 897 apps with less than a third of them connected.
The old playbook of copying everything into one place does not work at AI scale. It is too slow, too expensive, and too risky for regulated industries.
Starburst offers something different. A zero-copy, governed, federated data access layer that connects your entire enterprise without moving a single byte. It brings AI to the data instead of the other way around. And with its 2025 releases (MCP server, agent API, vector store access, Iceberg-native catalog), it has evolved from a query engine into a genuine AI infrastructure platform.
The winners in the AI race will not be the companies that move the most data. They will be the ones that access the right data, in the right place, at the right time, without moving it at all.
So here is the question worth asking: is your current data stack actually ready for AI, or are you still building pipelines that should not need to exist?



