Introduction
Apache Spark, a powerful data processing tool to counter the attacks of Big Data. It became the game changer once it became open-source in 2014. Being the prominent leader in terms of processing or analyzing Big Data. There was the requirement to make some significant changes or updates in Spark, to be a leader in the future as well. Recently a new version of Apache Spark (3.1.1) is being released and here are some of the Key Features, which make it a much more effective tool for processing and analysis.
- For improving the pushdown, pluggable Data Catalog is added under the hood of Datasource V2. It provides the unified APIs for streaming and batch processing.
- For making the optimized results while execution of Query, Adaptive Query Execution is added into the armor of Apache Spark 3.x.
- Dynamic Partition Pruning is introduced for the faster execution of the queries having filters and scanning on two different tables.
- New visualization feature is added into the Structure Streaming UI for better monitoring.
- Now you can analyze the cached data inside Spark 3.x which is one of the most wanted features from Spark.
And many more minor changes…

Overall 3400 jira tickets have been resolved. Although there is no major change made in terms of coding. So there is no worry to change your already existing code in the environment of Spark.
(Source: https://databricks.com/blog/2020/06/18/introducing…)
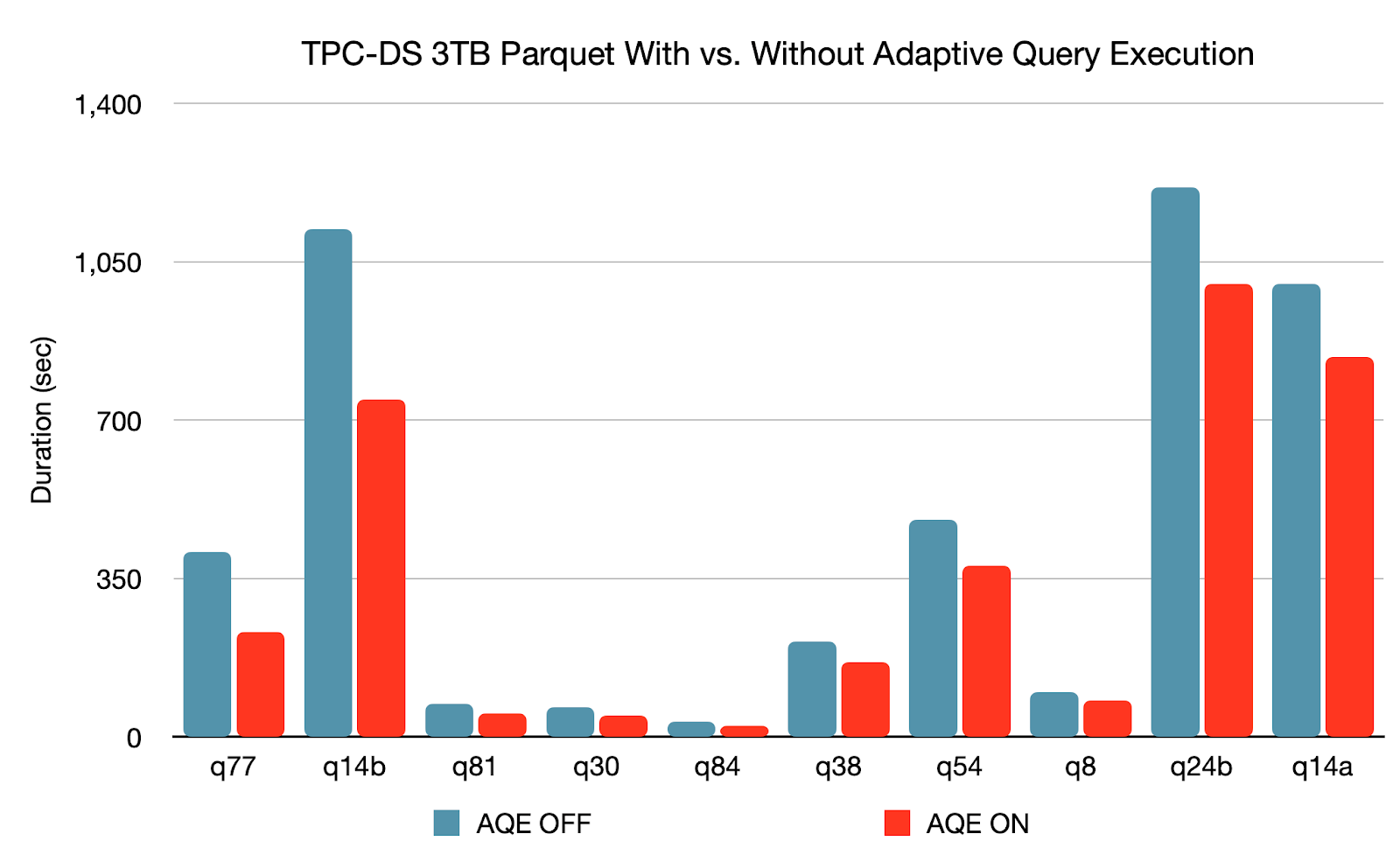
Let’s discuss a bit more about Adaptive Query Execution and Dynamic Partition Pruning.
Adaptive Query Execution makes better optimization decisions during query execution. It interprets the size of the table and automatically changes from Sort Merge Join into a Broadcast join and so on, if one of the tables is small.
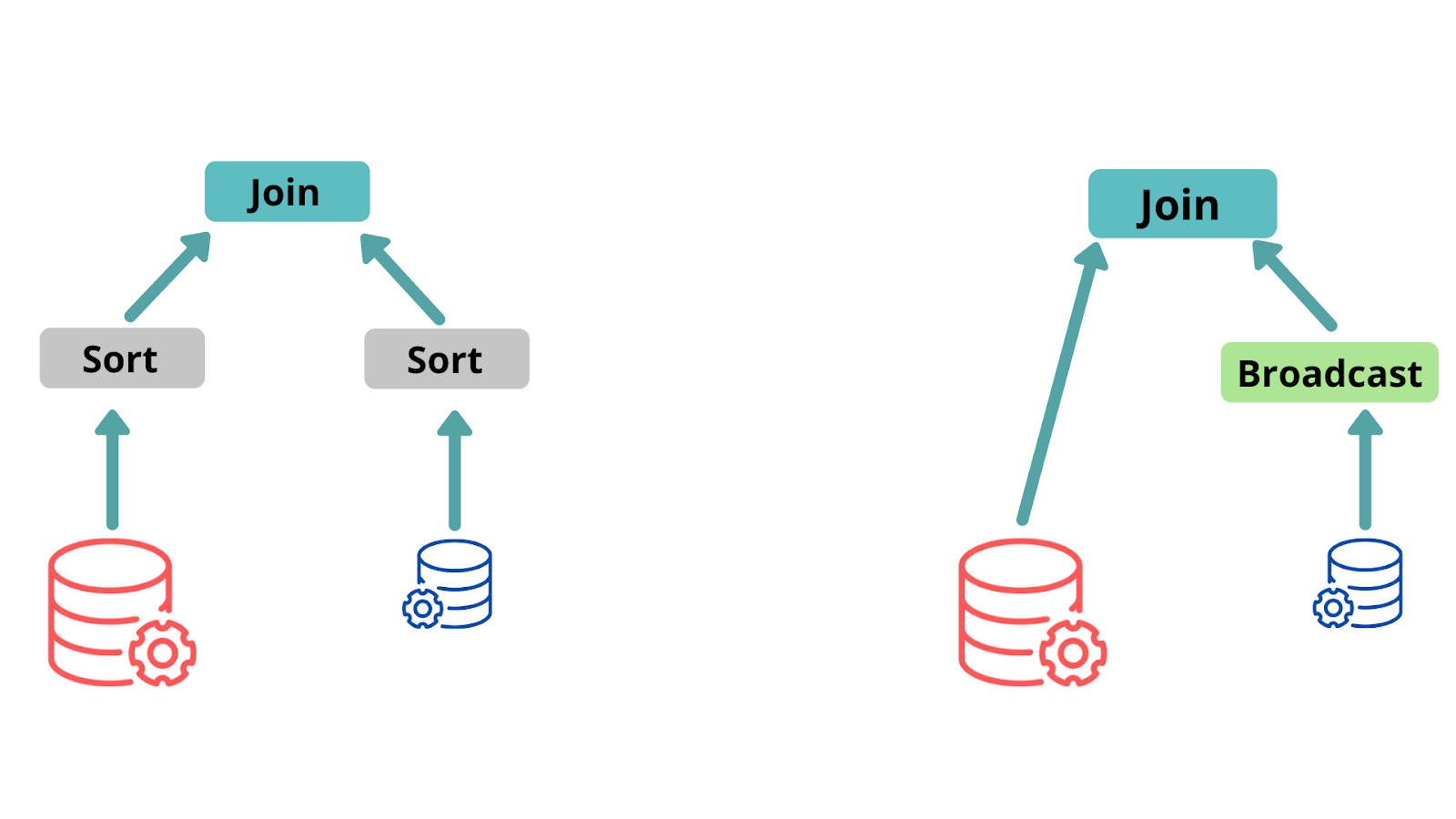
This release introduces three major adaptive optimizations:
- Dynamically coalescing shuffle partitions simplifies or even avoids tuning the number of shuffle partitions. Users can set a relatively large number of shuffle partitions at the beginning, and AQE can then combine adjacent small partitions into larger ones at runtime.
- Dynamically switching join strategies partially avoids executing suboptimal plans due to missing statistics and/or size misestimation. This adaptive optimization can automatically convert sort-merge join to broadcast-hash join at runtime, further simplifying tuning and improving performance.
- Dynamically optimizing skew joins is another critical performance enhancement, since skew joins can lead to an extreme imbalance of work and severely downgrade performance. After AQE detects any skew from the shuffle file statistics, it can split the skew partitions into smaller ones and join them with the corresponding partitions from the other side. This optimization can parallelize skew processing and achieve better overall performance.
(Source: https://databricks.com/blog/2020/06/18/introducing…)
Dynamic Partition Pruning, based on the dimension table (Small table) filter query fact table (Large table) will also be filtered making the joins easier and optimal.
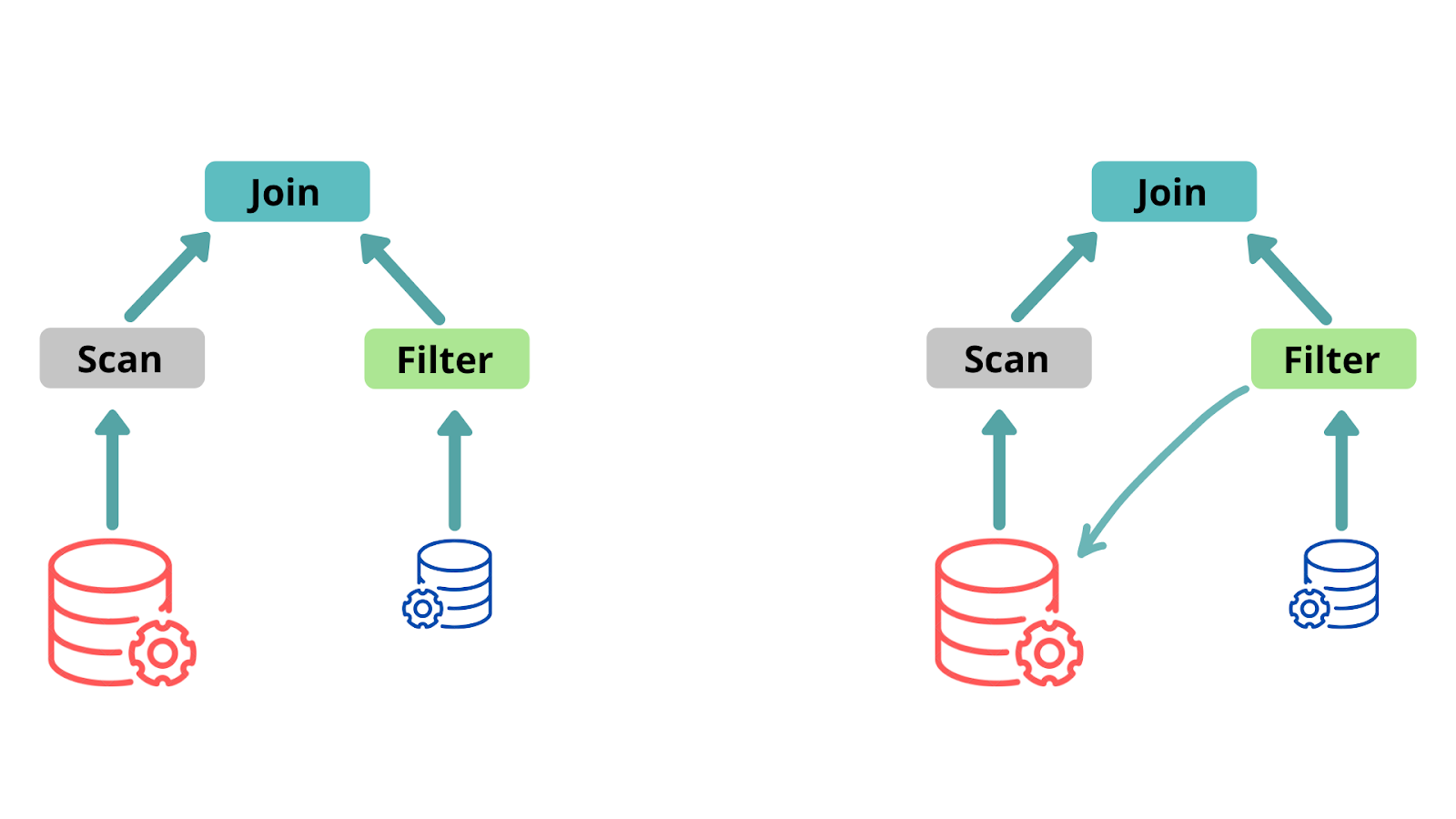
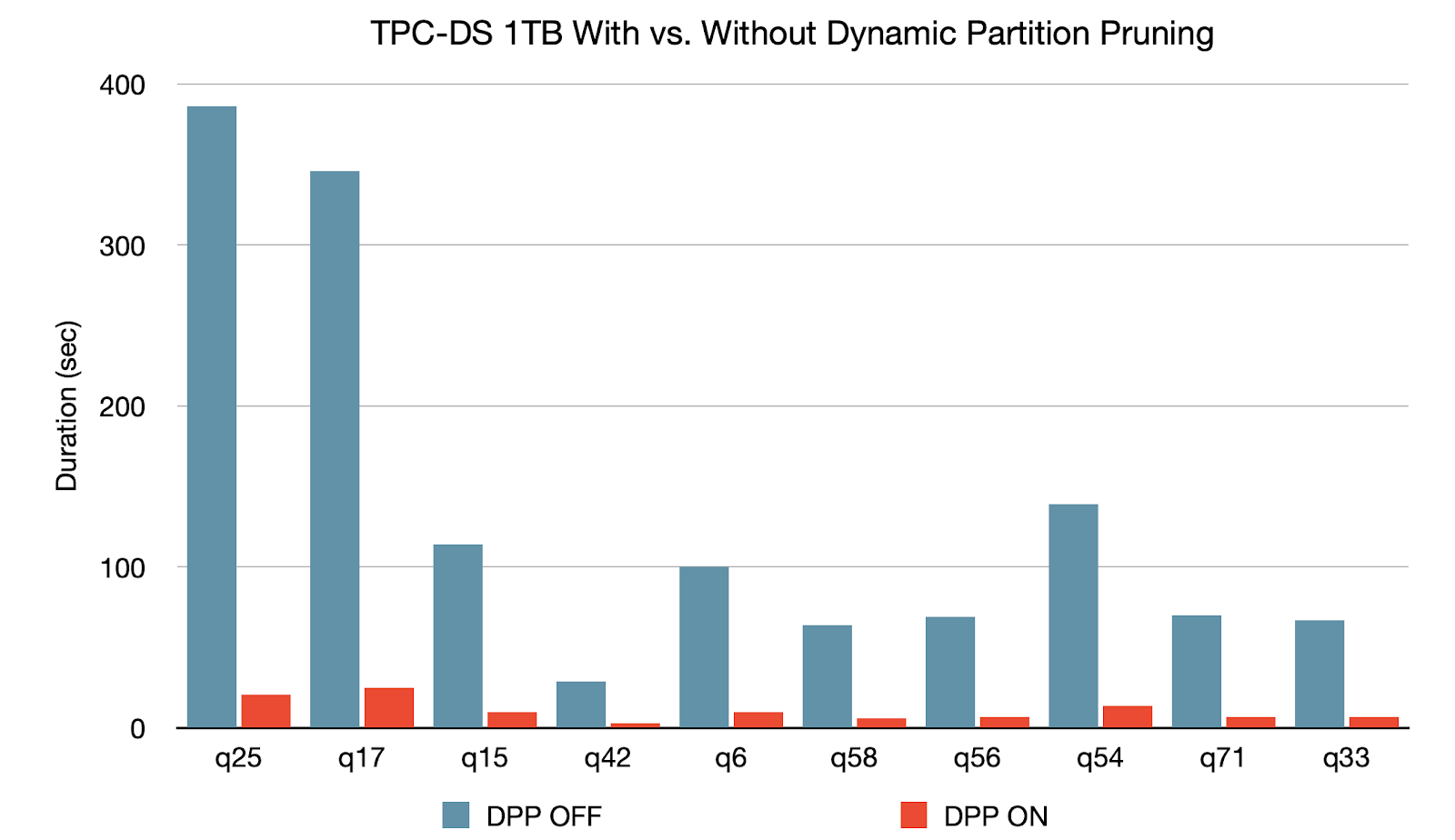
(Source: https://databricks.com/blog/2020/06/18/introducing…)
Want to dive deep into these concepts with hands-on experience? We have had a detailed discussion on these features in our free meetup session (meetup.com/all-things-data). Take a look at our recorded meetup sesion:
Want to try hands-on yourself and worry about writing the code all by yourself? Don’t worry we have taken care of that as well. Visit our youtube channel and in the description, you would find the hands-on notebooks.
Did you like our video? Want to explore more such content related to the latest technologies? Join our meetup family of having 3200+ members, for re-equipping yourself with various new technologies for free. Click here now to join our knowledge sharing family.
Conclusion
Apache Spark has reequipped itself with some of the most demanded and required features into its armor. Because of which it has become the one of the best tools to tackle the huge amount of data generated from various sources at various speeds easily and effectively.