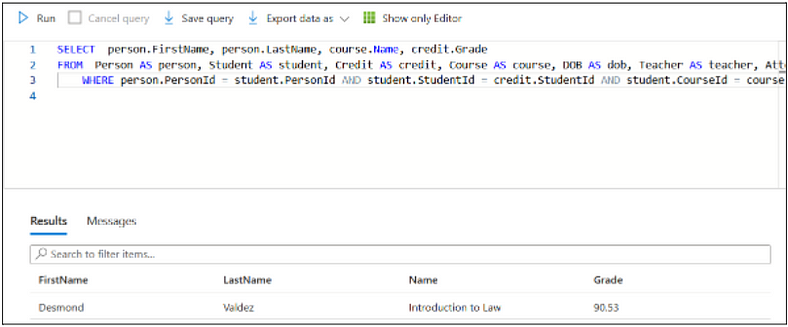
Hands-On: Implementing Star and Snowflake schemas in Azure SQL
Step 1: Setting up the Environment
To get started with Azure SQL, first of all search for SQL Database in the search bar and select the SQL Databases.
Now, click on the “+ Create” button present on the top left section of the page.
Under the Basic tab, select your Resource group. Then give a name to your database (in our case it’s dcdemo). Finally click on the Create new button in front of the Server option.
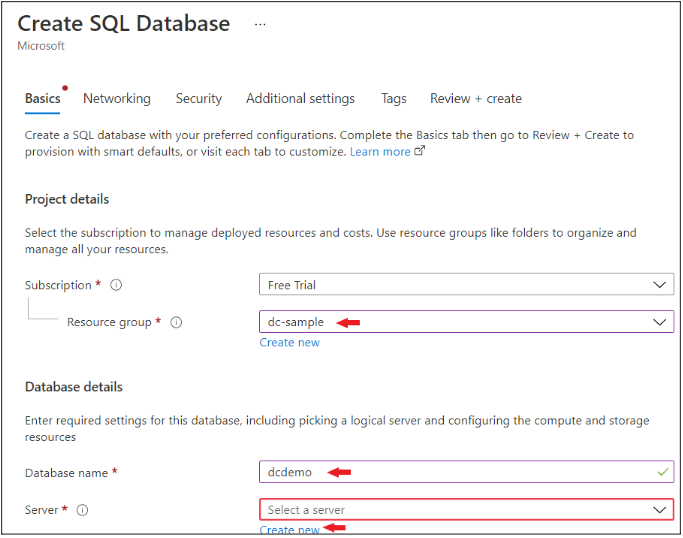
Now, give your server a name (in our case it’s dcdemoserver), then enter admin as your username and create a password as well.
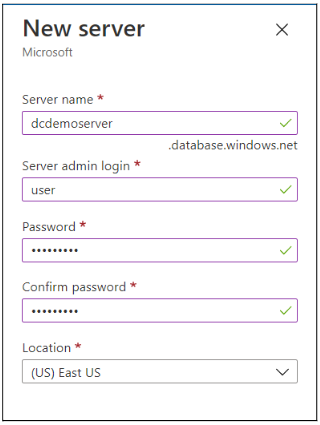
Once this is done, click on the Create button.
Go to Additional Settings tab and for Use existing Data select Sample.
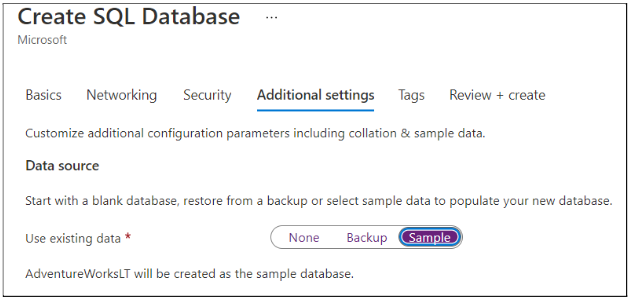
After this, click on the Review + Create button.
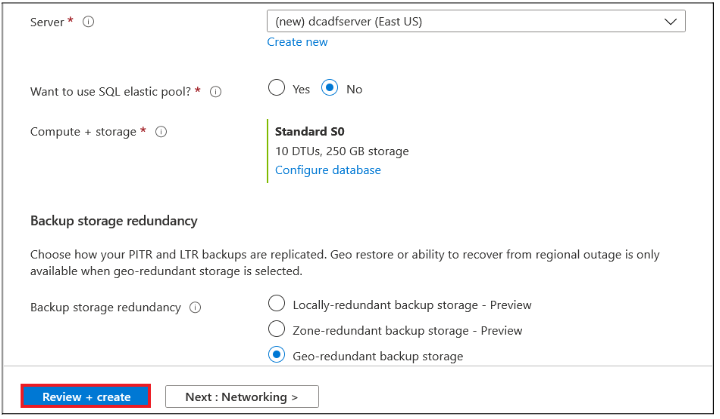
Then, finally click on the Create button.
It will take 2-3 minutes for creating the SQL Database.
Now, go to the Resource Group and click on the SQL Database that you have created.

From the leftmost section, click on the Query Editor (Preview) button.

It would ask for the username and password that you have created during the creation time of the server. Enter user id & password and click on OK.
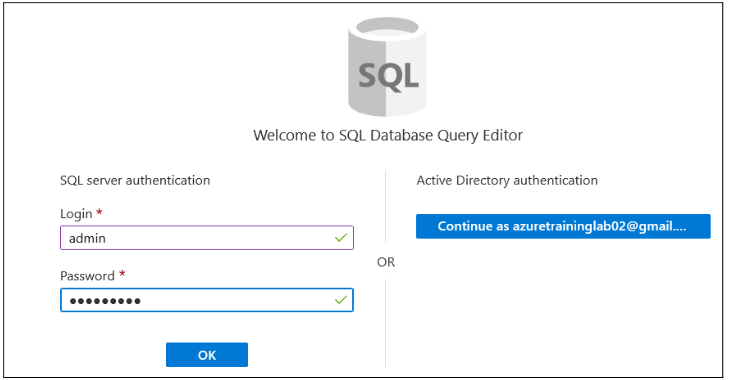
Note: If you would be get this error message:

To resolve this error, we must add our IP into the firewall of the server that we have created.
For doing so, open the Resource group from home in a separate tab and click on the server that you have created.
Now, from the leftmost section, scroll down to Security and click on Firewall and Virtual Networks.
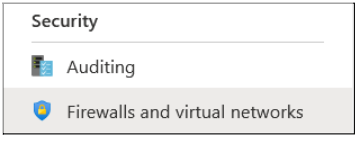
After this, click on + Add Client IP” button and then click on save.

Your IP gets added into the firewall automatically.

Now, let’s head back to the login page for SQL Database and try again. This time we would be able to login to the system successfully.
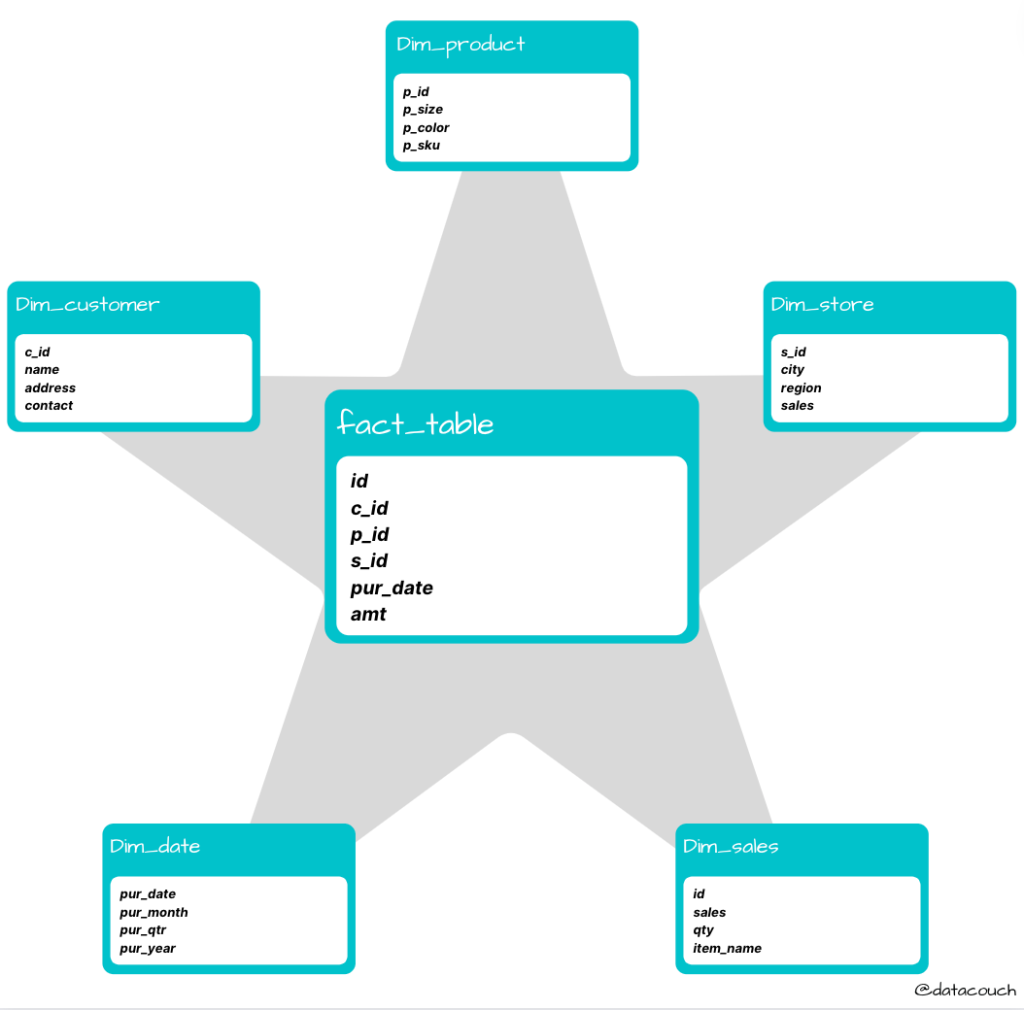
Step 2: Working with Star Schema
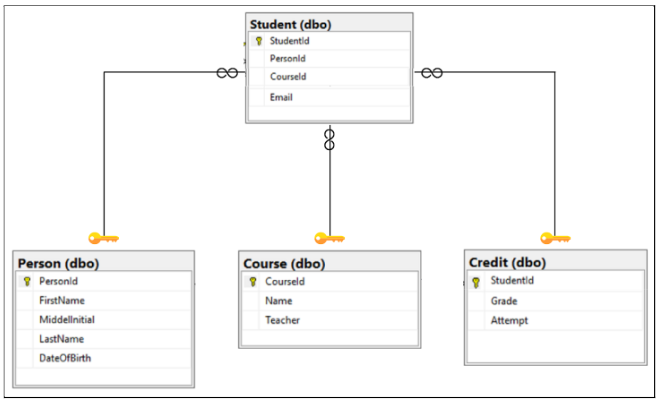
First of all let’s create a Star Schema within Azure SQL. So let’s see what does our Star Schema look like:
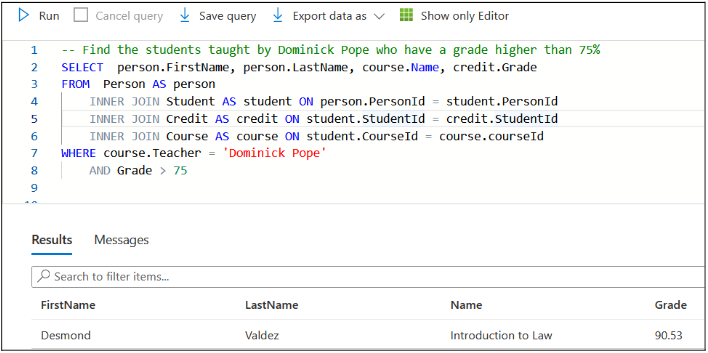
Step 3: Working with Snowflake Schema
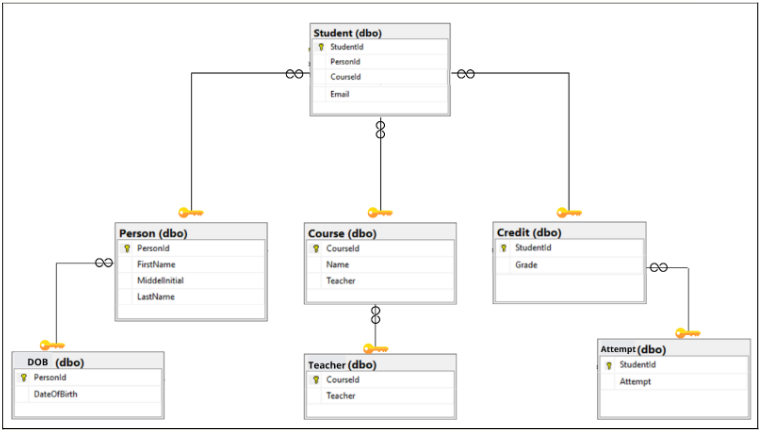
Now, let’s see how our normalized Snowflake schema would look like for the above example:
Before running the commands to create the tables in the snowflake schema, kindly make sure you have run the drop command for all the tables created with star schema.