
What Is an AI Factory and Why Every Enterprise Needs to Build One Now
What is an AI factory? A specialized computing infrastructure purpose-built for the entire AI lifecycle: training models, running inference, powering agentic workflows, and manufacturing intelligence from raw data at enterprise scale.
For most of the last two decades, the data center was a cost center. It stored things. It moved things. It kept the lights on for the business systems that actually created value. The measure of success was uptime and cost per gigabyte.
That model is being replaced, and the replacement is happening faster than most enterprise infrastructure teams have planned for. The data center is becoming an AI factory: a production system whose output is not stored data but manufactured intelligence, measured not in gigabytes but in tokens, reasoning, and automated decisions per second.
The numbers behind this shift are not speculative. According to Gartner, worldwide AI spending will reach $2.52 trillion in 2026, a 44% increase year-over-year. Building AI foundations alone is driving a 49% increase in spending on AI-optimized servers. This is not an incremental investment. It is an infrastructure paradigm shift.
This guide explains what an AI factory actually is, how it differs from the infrastructure you have today, what it takes to build one, and why the organizations that start building now will have a structural advantage that cannot be replicated by late movers.
What Is an AI Factory, Really?
The term was popularized by NVIDIA CEO Jensen Huang, who described the AI factory as infrastructure that does not just store and process data but manufactures intelligence at scale. In Huang’s framing, the AI factory is the third great infrastructure revolution, following electricity and the internet.
The core idea is a shift in what infrastructure is for. A traditional data center is built around retrieval: store data, retrieve it when needed, run applications that process it. An AI factory is built around production: take raw data as input, run it through training and inference pipelines, and produce intelligence as output — decisions, predictions, recommendations, and automated actions.
The New Metric: Tokens Per Second, Not Gigabytes Per Server
In an AI factory, the fundamental unit of output is the token — the smallest unit of AI-generated text, code, or reasoning. According to NVIDIA’s own engineering documentation, AI factories unify five critical layers — energy, chips, infrastructure, models, and applications — into a system optimized for the demands of agentic AI, physical AI, and high-performance compute. Infrastructure teams that still measure their AI deployments in CPU utilization and storage capacity are measuring the wrong thing.
The right question is: how many tokens can your infrastructure produce per second, per watt, and per dollar? That question reframes infrastructure from a cost to be minimized into a production asset to be optimized.
Traditional Data Center vs. AI Factory: The Difference That Matters
Most enterprises today have data centers. Very few have AI factories. The gap between the two is not just hardware. It is architecture, purpose, governance, and how the organization thinks about the economic value of its infrastructure.
| Dimension | Traditional Data Center | AI Factory |
|---|---|---|
| Primary purpose | Store and retrieve data, run general business applications | Manufacture intelligence: train models, run inference, power agentic workflows |
| Core workload | CPU-based transactional and analytical processing | GPU/accelerator-based AI training, fine-tuning, and inference at scale |
| Key metric | Uptime, storage capacity, throughput in GB/s | Token production per second, inference latency, GPU utilization percentage |
| Architectur | General-purpose servers, standard Ethernet networking | Accelerated computing clusters, high-bandwidth networking (InfiniBand/Spectrum-X) |
| Data role | Data is stored and queried | Data is the raw material that the factory converts into intelligence |
| ROI model | IT cost center — minimize spend per workload | Direct production system — maximize intelligence output per dollar invested |
| Scaling approach | Add more storage and compute capacity as needed | Scale training and inference pipelines based on token demand and model complexity |
| Governance requirement | Standard IT security, access management, and backup | AI-specific governance: data provenance, model monitoring, access controls per role |
AI infrastructure spending will reach $1.37 trillion in 2026, up from $965 billion in 2025 — a 42% single-year increase. IDC projects AI infrastructure spending will reach $758 billion by 2029 in the accelerator server segment alone.
Source: Gartner AI Spending Forecast, January 2026 / IDC Worldwide Infrastructure Tracker, October 2025
The Five Layers of an Enterprise AI Factory
An AI factory is not a single product or a single purchase. It is a stack of five interdependent layers, each of which must be designed, governed, and optimized as part of a unified system. Organizations that build one layer without the others end up with expensive compute that underperforms, as DataCouch’s own manufacturing client experienced before engaging our infrastructure team.
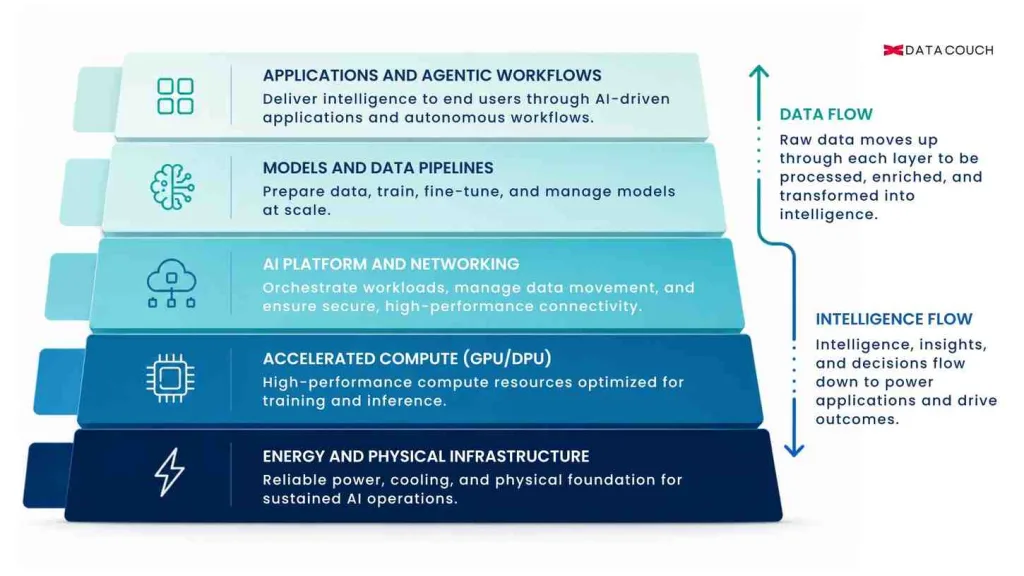
Layer 1: Energy and Physical Infrastructure
The foundation of every AI factory is power and cooling. GPU clusters consume dramatically more power per rack than traditional servers. Before deploying accelerated compute, enterprises must assess their power capacity, cooling architecture, and physical space constraints. An underpowered facility is the most common reason AI factory projects stall before they begin.
Layer 2: Accelerated Compute: GPUs, DPUs, and NPUs
AI training and inference are GPU workloads, not CPU workloads. This layer covers the selection, configuration, and optimization of accelerated computing hardware. The critical decision here is not just which GPU to buy — it is how to schedule workloads across the cluster, allocate compute quotas per team and use case, and monitor utilization in real time. DataCouch’s manufacturing client saw GPU utilization rise from under 5% to over 90% by addressing workload scheduling, networking, and access controls at this layer.
Layer 3: AI Platform and Networking
High-bandwidth networking is as important as computing in an AI factory. Data must move between GPUs faster than standard Ethernet allows. This layer covers the networking fabric, storage architecture, and the orchestration platform that manages how workloads move through the system. Cluster management, monitoring dashboards, and security controls are configured at this layer before any models are deployed.
Layer 4: Models and Data Pipelines
This is where raw data becomes intelligence. The data pipeline layer covers ingestion, cleaning, labeling, and the movement of data into training and fine-tuning workflows. Real-time data streaming platforms, federated query layers, and vector databases all operate here. Data governance — provenance tracking, access controls, schema validation — must be embedded at this layer. This is the layer most enterprises underinvest in and most regret ignoring.
Layer 5: Applications and Agentic Workflows
The output layer of the AI factory. This is where AI capabilities are surfaced to business users: analytics dashboards, AI assistants, automated decision engines, and agentic workflows that plan and execute tasks across enterprise systems. The governance requirements here are the most visible because this is where AI decisions touch real business processes and real customers.
Want to assess your organization's AI factory readiness across all five layers?
The Layer Most Enterprises Forget: The People Running It
Here is the insight that NVIDIA’s architecture diagrams do not include. An AI factory without trained operators is not a factory. It is an expensive, underutilized asset.
McKinsey’s analysis shows that AI could add $13 trillion to global GDP by 2030, but also notes that capturing this value requires organizations to rewire their operating models, not just their infrastructure. The rewiring starts with the people behind the infrastructure. A manufacturing enterprise that deploys a GPU cluster without training its data engineering and operations teams on workload scheduling, model monitoring, and AI governance will see GPU utilization remain below 10%. DataCouch has seen this exact pattern repeatedly, and it is the most preventable form of AI infrastructure waste.
The four pillars that DataCouch applies to every AI factory engagement address this directly.
- Custom Training: AI factory operations training covering GPU workload scheduling, model deployment, inference optimization, and governance practices for the specific teams running the infrastructure
- AI Consulting: Architecture design, layer-by-layer readiness assessment, platform selection, and data governance framework for the AI factory stack
- Custom AI Solutions: Bespoke model deployment, fine-tuning pipelines, and agentic workflow development built on the AI factory infrastructure
- Custom Coaching: Ongoing support for infrastructure leads, data architects, and AI platform owners as the factory scales and the technology evolves
On-Prem, Cloud, or Hybrid: Where Should Your AI Factory Live?
This is the most common question enterprises ask when starting an AI factory project, and it does not have a universal answer. It has a contextual one based on three factors: data sovereignty requirements, latency needs, and total cost of ownership at scale.
On-Premises AI Factory
On-prem is the right choice when data cannot leave the organization’s physical control: regulated financial institutions, government agencies, healthcare organizations, and defense contractors. It is also the right choice when AI workloads require consistent ultra-low latency that cloud round-trips cannot guarantee. The trade-off is higher upfront capital expenditure and the operational responsibility of managing the infrastructure.
Cloud AI Factory
Cloud-based AI factory deployments offer speed to production and elasticity that on-prem cannot match for variable workloads. Organizations in the early stages of AI adoption, running highly variable training jobs, or without the operational capacity to manage their own infrastructure, benefit from cloud deployment. The trade-off is ongoing operational cost at scale and, for some industries, data residency limitations.
Hybrid AI Factory
Most mature enterprise AI factory deployments end up hybrid. Sensitive training data and high-stakes inference workloads stay on-premises. Burst workloads, experimental training runs, and globally distributed inference use cloud capacity. The challenge of hybrid governance is ensuring that data policies, access controls, and model monitoring apply consistently across both environments.
Gartner projects enterprises will spend more than $37 billion on AI-optimized infrastructure as a service by 2026. 40% of enterprises are expected to adopt hybrid AI architectures by 2028, up from 8% today.
Source: Gartner, October 2025
We specialize in custom AI programs and globally recognized certification training at scale.
Is Your Enterprise Ready to Build an AI Factory? Use This Checklist.
Before committing capital to AI factory infrastructure, every enterprise should be able to answer the following questions honestly. The organizations that skip this step are the ones that end up with GPU clusters running at 5% utilization.
| Readiness Area | Questions to Answer Before You Build |
|---|---|
| Data Foundation | Is your data clean, labeled, and governed? Do you have a data policy that defines provenance, access, and retention before a single model is trained? |
| Compute Strategy | Have you assessed on-prem vs cloud vs hybrid GPU infrastructure based on your sovereignty, latency, and cost requirements? |
| Governance Framework | Do you have AI-specific access controls, model monitoring, and accountability chains defined before deployment? |
| Team Capability | Does your team have the skills to operate an AI factory? Deployment without trained personnel is infrastructure waste. |
| Partner Ecosystem | Have you identified the right technology partners for your specific workloads — streaming, data federation, graph intelligence, model orchestration? |
| ROI Measurement | Have you defined the KPIs you will use to measure AI factory output — token throughput, inference cost per query, business outcome per model? |
What DataCouch Brings to Enterprise AI Factory Deployments
Most technology vendors will sell you the hardware layer and the software layer of an AI factory. Very few will help you build the governance layer, train the people layer, and design the data pipeline layer simultaneously.
DataCouch’s role in AI factory engagements spans all five layers of the stack. We are certified across the partner platforms that power each layer: Confluent and Redpanda for real-time data pipelines, Starburst for federated data access without movement, Databricks for model development and MLOps, Snowflake for governed data warehousing, and Neo4j for knowledge graph intelligence. We have delivered AI infrastructure outcomes, including GPU utilization improvements from under 5% to over 90% in manufacturing environments, governed on-prem compute deployments for sovereign AI requirements, and AI upskilling programs that directly reduced the human gap between infrastructure capability and operational performance.
The AI factory is not a product you deploy once. It is a capability you build continuously. That requires a partner who understands the full stack from the silicon to the people running it.
Key Takeaways: What to Remember as You Plan Your AI Factory
- An AI factory is not a data center with more GPUs. It is a fundamentally different architecture designed to manufacture intelligence as a production output, not store data as a cost center.
- The five layers — energy, compute, platform, data pipelines, and applications — must all be designed and governed as a unified system. Investing in one layer without the others is the most common cause of expensive underperformance.
- GPU utilization below 10% is not a hardware problem. It is a governance, scheduling, and training problem. The most valuable infrastructure investment you can make alongside the hardware is training the people who operate it.
- On-prem, cloud, and hybrid each serve different requirements. The decision must be driven by data sovereignty, latency, and total cost of ownership — not by vendor preference or market momentum.
- Worldwide AI infrastructure spending will reach $1.37 trillion in 2026. The organizations building AI factory capability now will have compounding advantages in model quality, operational efficiency, and institutional knowledge that cannot be bought later.
- Governance is not the last step. It is the first. No AI factory should go into production without defined data policies, access controls, and model monitoring in place.
Here is the question every infrastructure decision-maker should be asking right now: Is your organization building an AI factory, or is it buying AI tools and hoping they add up to the same thing?
They do not add up to the same thing. The factory is a system. The tools are components. The difference is in architecture, governance, and the people trained to run both.




