
AI Factory: The New Engine of Enterprise Innovation
The Uncomfortable Truth About Enterprise AI
Here is a pattern most enterprise leaders recognize. A proof-of-concept runs beautifully in a controlled environment. Stakeholders are excited. Then someone asks when it ships to production, and the entire initiative quietly stalls.
Talent is not the problem. Budget usually is not either. The architecture is.
NVIDIA CEO Jensen Huang put it plainly when he introduced the AI Factory concept: enterprises do not just need infrastructure that stores or moves data. They need infrastructure that manufactures intelligence, continuously, reliably, at scale. That framing has aged well. In 2026, it describes exactly the gap separating enterprises that are extracting real value from AI and those still running pilots.
Hiring more engineers will not close this gap, and increasing cloud spend alone will not solve it either. The issue is not effort or investment, but how AI systems are designed to operate. What enterprises need is a production model built for continuous, reliable AI delivery. That is what an AI Factory provides.
What Is an AI Factory?
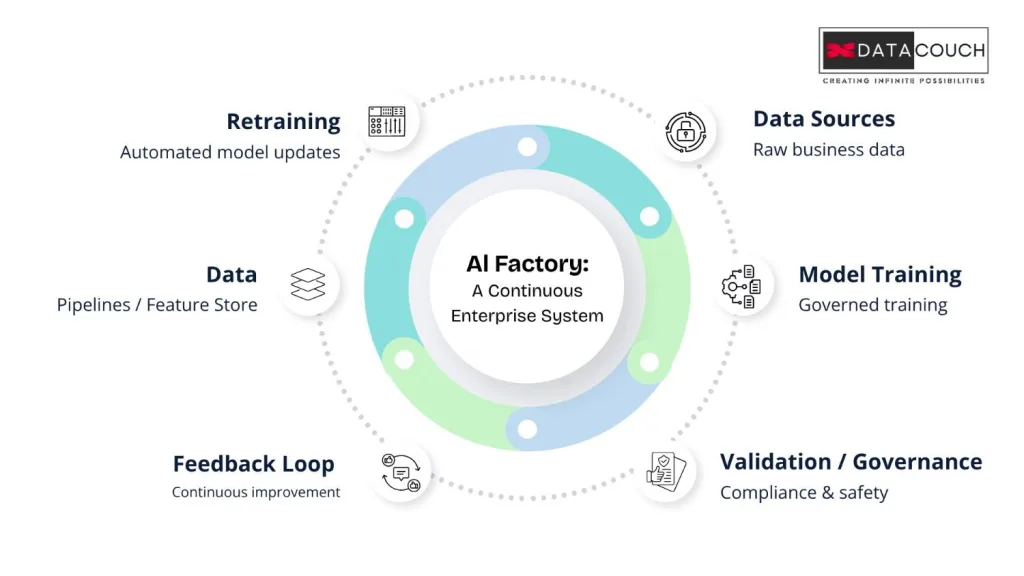
Not a product. Not a platform you purchase and deploy in a weekend. In an enterprise context, an AI Factory is a continuously operating production system that takes raw business data, converts it into trained and validated models, deploys those models where they are needed, and feeds real performance signals back into the next training cycle. Without manual hand-holding at each stage.
The loop looks like this: data feeds models, models get deployed, deployment generates feedback, feedback sharpens the next model. Round and round, automatically.
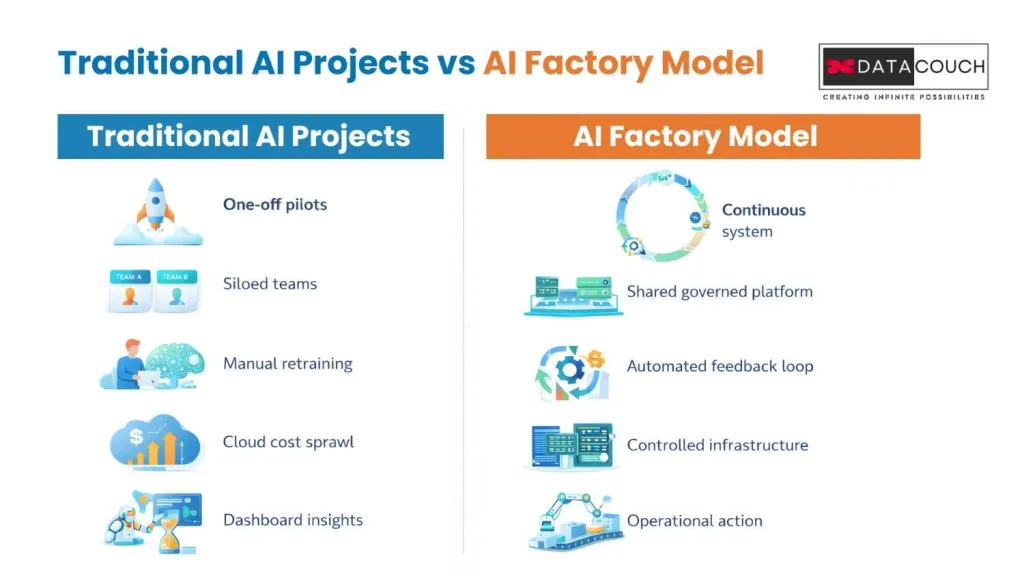
Most enterprise AI today is project-centric. One team builds a fraud model. Another builds a demand forecasting model. Each lives in its own silo, requires its own maintenance, and hits its own scaling wall. An AI Factory is platform-centric instead. One governed infrastructure layer serves every AI workload across the organization. Each new use case you add is faster and cheaper to deliver than the one before it. That compounding effect is the real business argument for making the shift.
Core Components of an Enterprise AI Factory
Five layers have to work together. Pull one out, and the whole production line slows down or breaks.
Intelligent Data Pipelines draw from ERP systems, IoT sensors, customer platforms, and external data sources. Feature stores are a detail that often gets overlooked early and causes serious problems later: they ensure the exact same data transformations applied during training are replicated at inference time. When that consistency breaks, model performance degrades in production in ways that are genuinely difficult to diagnose.
Scalable Model Training Systems treat training as a governed workflow, not a manual task someone kicks off when they remember to. Drift signals, business events, or scheduled cadences trigger retraining automatically. Distributed training across GPU clusters, paired with automated validation pipelines, means only production-ready models move forward.
On-Premises GPU Infrastructure provides the compute backbone. Training and inference run without the latency spikes, variable costs, and data exposure risks that come with pure cloud setups.
MLOps and Orchestration handle everything from code commit to full rollout: staging, testing, canary releases, drift monitoring, and rollback controls. Platforms like Dataiku are built specifically to wire these stages together inside a governed workflow rather than leaving teams to stitch disparate tools together manually.
Agentic AI is the component that most enterprises either underestimate or misunderstand. These are not chatbots. Agentic systems perceive context, reason across multiple tools and data sources, and execute multi-step decisions without waiting for human approval at each step. In practice, this is the difference between an AI Factory that produces intelligence and one that actually puts it to work.
On-Prem GPU and Agentic AI: Where the Real Leverage Lives
Cloud GPU APIs make sense at low utilization. At the steady-state inference volumes a production AI Factory generates across dozens of concurrent workloads, the economics tell a very different story. On-premises infrastructure removes unpredictable pricing, keeps utilization under direct enterprise control, and produces cost structures that are actually forecastable.
Four reasons enterprises are moving compute on-premises right now:
- Data sovereignty: BFSI, healthcare, and defense organizations cannot legally or practically route sensitive training and inference data through third-party APIs. On-prem keeps it inside the perimeter, full stop.
- Latency: Real-time applications like fraud detection and quality inspection need sub-100ms inference. Cloud round-trips at scale simply cannot guarantee that consistently.
- Cost structure: CapEx infrastructure amortized over three to five years holds up far better than OpEx cloud spend that scales linearly with every new agentic workflow added to the factory.
- Compute right-sizing: NVIDIA’s MIG technology allows GPU capacity to be partitioned per workload. A 7B parameter model does not need the same VRAM allocation as a 70B model, and over-allocating that compute across dozens of workloads adds up fast.
That said, computing alone does not move the needle on business outcomes. Agentic AI is what does. A conventional system flags that a stockout is likely in 72 hours. An agentic system goes further: it raises the purchase order, reroutes logistics, updates the ERP, and notifies relevant teams, all within governance boundaries defined by the business. The prediction and the response happen in the same loop.
DataCouch's Agentic AI development programs are specifically built to help enterprise teams move from architectural intent to governed production deployment.
Real Enterprise Use Cases
Manufacturing is where AI Factory ROI tends to show up fastest and most clearly. Models score equipment health continuously against historical failure patterns. Agentic systems respond to anomaly signals automatically, scheduling maintenance windows, dispatching engineer notifications, and updating CMMS records without waiting for a human to connect the dots. Unplanned downtime drops by as much as 35% in mature deployments. Quality inspection models running at line speed cover 100% of output rather than relying on sampling, with defect signals feeding back into the training loop on a daily cadence.
GCCs are at a genuine strategic inflection point. India’s 1,800 and growing Global Capability Centers face a real choice: build 15 separate AI stacks for 15 business units, each requiring its own infrastructure and maintenance overhead, or build one centralized AI Factory that serves all of them from a single governed hub. The ones moving fastest are cutting sprint cycles by 30 to 40% through agentic code generation pipelines and delivering against parent enterprise AI demands without scaling headcount proportionally. DataCouch’s GCC AI enablement programs address the infrastructure side and the workforce readiness side together, because solving one without the other does not hold.
Large enterprises are seeing the clearest returns in three areas: customer support automation, fraud detection, and compliance monitoring. Support models trained continuously on live ticket data feed agentic systems that handle Tier 1 and Tier 2 queries without human involvement, cutting handling time by 50 to 70%. Fraud models retrained within 24 to 48 hours of drift detection adapt to new attack patterns far faster than any quarterly update cycle could. Compliance agents generate audit trails across communications and transactions automatically, which matters significantly for teams operating under GDPR, SEBI, RBI, or FDA requirements.
The Business Case in Plain Numbers
Enterprises running mature AI Factory infrastructure report consistent outcomes:
- Infrastructure and cloud spend fall 40 to 60%
- Model deployment speed increases three to five times over traditional approaches
- Manual decisioning volumes drop by more than 70% where agentic systems are deployed
- Data stays 100% within the enterprise perimeter on on-prem setups
What this means in practice is that scalability stops being a per-project negotiation and becomes an architectural given.
Challenges Worth Naming
Data silos are almost always the first real obstacle. Fragmented data spread across legacy ERPs, cloud warehouses, and SaaS platforms cannot feed an AI Factory effectively without a unified data layer sitting underneath. DataCouch’s data engineering consulting helps enterprises design that foundation with governance built in from the start rather than bolted on later.
Infrastructure cost clarity requires separating steady-state workloads from burst and POC workloads in the financial model. On-prem wins at scale. Cloud remains useful for experimentation and variable demand. A hybrid model handles both without forcing an all-or-nothing commitment to either.
Talent gaps are more common than most organizations want to admit publicly. Engineers who combine MLOps, DevOps, data engineering, and production AI experience are genuinely rare. DataCouch’s enterprise training pathways build that capability from within rather than creating a dependency on external vendors to keep the lights on.
Why Enterprises Work with DataCouch
DataCouch has operated at the intersection of enterprise AI infrastructure and capability building since 2016. With over 300,000 professionals trained globally and deep partnerships with Confluent, Snowflake, Neo4j, and Dataiku, the positioning is specific: where infrastructure architecture and workforce readiness are treated as one problem, not two.
That integration matters more than it sounds. Building an AI Factory without a team capable of running it produces technical debt faster than it produces value. Training teams on tools they will never operate in a governed production environment produces certificates, not outcomes. DataCouch addresses both sides together, which is why enterprise engagements tend to hold long after the initial build is complete.
Key Takeaways
- An AI Factory replaces fragmented, one-off AI projects with a permanent, self-improving production system built to scale across every business function.
- On-prem GPU is a strategic decision about control: over the compute, the data, and the compliance posture.
- Agentic AI is what moves model outputs off the dashboard and into actual operational outcomes.
- The numbers hold up: infrastructure costs fall 40 to 60%, deployment cycles shrink three to five times, and automation gains compound with every new use case added to the factory.
- Enterprises that build this infrastructure now are not just moving faster. They are making the gap structurally harder for competitors to close.
Ready to Build Your AI Factory?
Six to twelve months is a realistic timeline to move from the current state to a production-ready AI Factory. Every month spent without one is a month your competitors are compressing their deployment cycles, reducing their inference costs, and automating decisions your teams are still making manually.
DataCouch works with enterprise CTOs, CIOs, and Heads of AI to assess current infrastructure gaps, design on-prem GPU and MLOps architecture aligned to actual compliance requirements, deploy agentic AI systems that generate measurable operational outcomes, and build the internal team that keeps the factory running independently long after the engagement ends.
The enterprises moving now will not just ship AI faster. They will build infrastructure that makes every future AI investment cheaper, faster, and more defensible than the one before it.
The gap between piloting AI and producing it at scale is an architecture decision. Make it now.
Frequently Asked Questions
A continuously operating production system that automates the full AI lifecycle: data ingestion, model training, validation, deployment, and feedback-driven retraining. A permanent enterprise capability, not a project with a delivery date.
Data stays inside the enterprise perimeter, costs become predictable at scale, and real-time inference latency stays within acceptable bounds. For regulated industries, these are architectural requirements, not optional preferences.
Traditional AI scales by adding engineers and spinning up isolated projects. An AI Factory scales horizontally through the same governed pipeline regardless of workload count. Each new use case becomes a configuration exercise rather than a six-month build.
Manufacturing, financial services, healthcare, and GCC-driven technology organizations see the strongest returns. High data volume, real-time decision requirements, and compliance complexity are the common denominators.




