AI Red Teaming: How to Test Your Enterprise AI for Vulnerabilities Before Attackers Do
What is AI red teaming? Adversarial testing of AI systems under simulated attack conditions to identify vulnerabilities, failure modes, and exploitable behaviours before behaviours are discovered and used by real attackers. NIST defines it as testing AI systems under stress conditions to seek out failure modes, not just confirming that the system works as expected.
Traditional security testing has a clear objective: find the vulnerabilities in your code before an attacker does. The scope is bounded. The attack surface is defined. The test produces a CVE list and a remediation backlog.
AI red teaming operates in a fundamentally different paradigm. An AI system does not have a fixed attack surface. The behaviour is probabilistic, not deterministic. The same input can produce different outputs on different runs. The vulnerabilities are not in the code alone. They are in how the model interprets language, how its training data was composed, how it responds to edge cases and adversarial inputs, and how it behaves when embedded in an agentic workflow with real permissions.
NIST’s AI Risk Management Framework positions adversarial testing as a core component of the Measure function, defining it as “an approach consisting of adversarial testing of AI systems under stress conditions to seek out AI system failure modes or vulnerabilities”. Yet according to industry research, 79% of organisations currently have an AI red teaming program and no requirement for adversarial testing before production deployment. This gap is where the next wave of enterprise AI incidents will originate.
Why AI Red Teaming Is Fundamentally Different From Traditional Penetration Testing
Traditional Software Is Deterministic. AI Is Not.
When a penetration tester probes a web application, the same malformed input produces the same exploitable behaviour every time. The vulnerability is reproducible, documentable, and patchable. AI systems do not work this way. A prompt that successfully jailbreaks an LLM on one run may produce a benign response on the next. This non-determinism means that AI red teaming cannot rely on the same methodologies, the same tooling, or the same pass/fail criteria as traditional security testing.
The Attack Surface Expands With Every New Capability
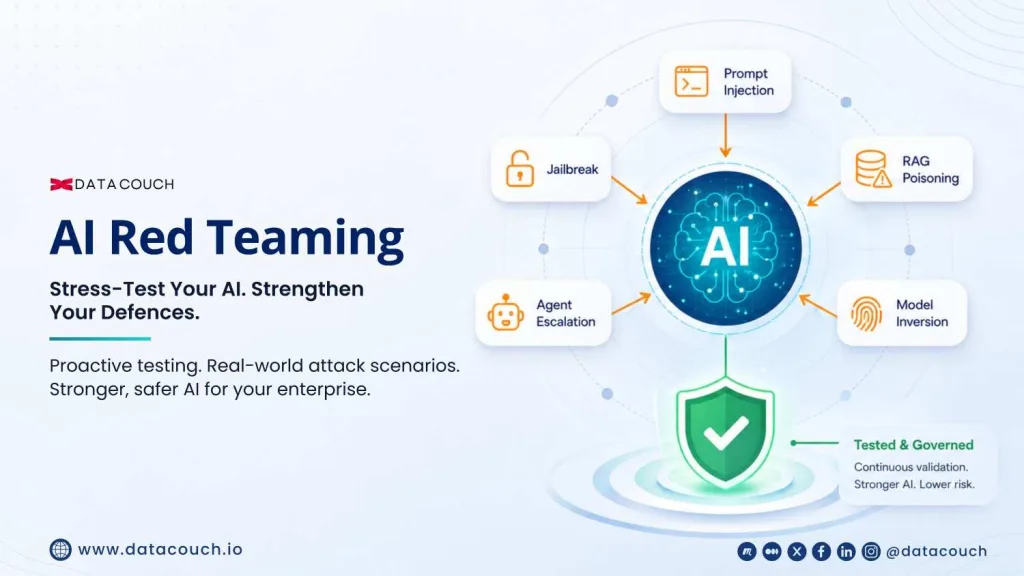
Every new AI capability your organisation deploys adds to the attack surface. A conversational AI assistant has one attack surface profile. That same assistant connected to a document retrieval system has a different profile that includes RAG poisoning. Connected to an email system, it gains another. Given agentic capabilities with real-world permissions, the attack surface expands again to include prompt injection through external content, agent privilege escalation, and tool misuse.
Why Sovereign AI Has Become an Imperative in 2026
NIST reported a greater than 2,000% increase in AI-specific CVEs since 2022. Prompt injection holds the number one spot on the OWASP Top 10 for LLM Applications 2025. Only 24% of enterprises have a dedicated AI security governance team.
Source: OWASP LLM Top 10, 2025 / NIST National Vulnerability Database
The Authoritative Frameworks That Define Enterprise AI Red Teaming
Three authoritative frameworks provide the structure for enterprise AI red teaming programs. Understanding what each covers and how they relate to each other is the prerequisite for building a defensible program.
NIST AI Risk Management Framework: Adversarial Testing as the Measure Function
The NIST AI RMF organises all AI risk management into four functions: Govern, Map, Measure, and Manage. Adversarial testing sits within the Measure function. NIST AI 600-1, the Generative AI Profile released in July 2024, extends this to identify 12 specific risk categories for generative AI systems, including confabulation, data privacy, information integrity, and security. The December 2025 draft Cybersecurity Framework Profile for AI (IR 8596) further bridges AI risk management with cybersecurity controls. The NIST AI RMF does not carry enforcement penalties, but US federal agencies now require it for AI procurements, and regulated enterprises use it as their internal governance standard.
MITRE ATLAS: The Taxonomy of AI-Specific Attack Techniques
MITRE ATLAS (Adversarial Threat Landscape for AI Systems) extends the ATT&CK framework specifically for AI threats. The October 2025 update added 14 new techniques focused on AI agents and generative AI systems. ATLAS now documents 15 tactics, 66 techniques, 46 sub-techniques, 26 mitigations, and 33 case studies drawn from real-world AI security incidents. For enterprise red teams, ATLAS provides the attack taxonomy for structuring test scenarios: it defines what to test for, what the attack technique looks like, and what mitigations address each technique.
OWASP Top 10 for LLM Applications: The Practitioner's Checklist
The OWASP Top 10 for LLM Applications 2025 provides the most widely used practical checklist for LLM security testing. Prompt injection remains number one, with supply chain vulnerabilities at number three. OWASP also released the Gen AI Red Teaming Guide in January 2025 and the Top 10 for Agentic Applications in December 2025, reflecting the expanded attack surface that agentic workflows introduce. For enterprise security teams, OWASP provides the checklist. MITRE ATLAS provides the taxonomy. NIST AI RMF provides the governance structure.
DataCouch integrates AI red teaming requirements into every enterprise AI deployment engagement.
What to Test: The Eight AI Attack Vectors Every Red Team Must Cover
| Attack Vector | What the Test Probes | Why It Matters for Enterprise |
|---|---|---|
| Prompt Injection | Embeds malicious instructions in user inputs, documents, emails, or web content that the AI processes, attempting to override its intended behaviour | Number behaviour SP LLM Top 10. Increasingly delivered through indirect channels (emails, PDFs, web pages) without user interaction |
| Jailbreaking | Uses carefully constructed inputs to bypass safety guardrails and produce outputs the model is designed to refuse | Tests whether safety controls hold under adversarial pressure. When GPT-5 launched in January 2026, red teams jailbroke it within 24 hours, per security researchers |
| RAG Poisoning | Injects malicious content into the retrieval knowledge base that the AI uses to answer questions | Research shows 5 crafted documents that can manipulate AI responses 90% of the time. Enterprise knowledge bases are soft targets |
| Model Inversion | Attempts to extract sensitive training data from the model through carefully constructed queries | Critical for models fine-tuned on proprietary or regulated data: can reveal PII, IP, or confidential business information |
| Agent Privilege Escalation | In agentic workflows, attempts to instruct the agent to act beyond its defined permissions through embedded instructions | Directly relevant as 40% of enterprise apps will integrate agents by the end of 2026. Agents with the end of real permissions require adversarial testing before deployment |
| Supply Chain Attack | Tests whether third-party AI models, plugins, or fine-tuned components introduce backdoors or unexpected behaviour | OWASP behaviorally chain vulnerabilities at number 3. Untested third-party AI components are the fastest-growing enterprise risk vector |
| Data Exfiltration via AI | Tests whether sensitive data can be extracted through multi-turn conversation or tool call sequences | Particularly relevant for AI assistants with access to internal databases, email systems, or document stores |
| Behavioural Drift Testing | Tests whether the model's behaviour changes in ways that introduce new vulnerabilities or bias | Ongoing monitoring requirement: a model that passes red team tests at deployment can drift into exploitable behaviour or through behavior or context window contamination |
How to Build an Enterprise AI Red Teaming Program: Five Steps
The organisations that organise AI red teaming programs approach it as a continuous practice, not a one-time audit. Here is the five-step framework for building that practice from the ground up.
Step 1: Build Your AI Asset Inventory
You cannot read what you cannot see. The first step is a complete inventory of every AI system in your organisation: deployed fine-tuned components, AI features embedded in SaaS tools, agentic workflows, and AI APIs called by internal developers. Gartner research found that 69% of cybersecurity leaders either suspect or have direct evidence that employees are using prohibited public GenAI tools. Without an inventory, your red team is testing a fraction of your real attack surface.
Step 2: Classify Systems by Risk Tier
Not every AI system requires the same depth of adversarial testing. A customer-facing AI assistant with access to internal databases requires more rigorous testing than an internal summarisation tool with access to non-sensitive documents. Classify each system using the EU AI Act risk categories (prohibited, high-risk, general-purpose, limited risk) and the NIST AI RMF’s context mapping function. This classification determines testing frequency, depth, and the specific attack vectors that apply.
Step 3: Map Attack Scenarios to MITRE ATLAS
Use MITRE ATLAS to translate each system’s risk profile into specific attack scenarios. For each AI system, identify which ATLAS tactics and techniques are applicable based on the system’s capabilities and access level. A system with external data ingestion faces RAG poisoning scenarios. A system with agentic capabilities and real-world permissions faces agent privilege escalation scenarios. Documenting this mapping creates the test plan and ensures coverage against known attack patterns rather than improvised testing.
Step 4: Execute Structured Adversarial Tests
Red teaming AI systems requires a combination of manual and automated testing. Manual testing by security researchers with AI-specific skills is essential for novel attack patterns and multi-turn adversarial conversations that automated tools miss. Automated testing using frameworks aligned to OWASP LLM Top 10 and NIST AI RMF provides coverage at scale across the full input space. The test results should be documented in the same format as traditional CVE reports: attack vector, evidence, severity classification, and recommended mitigation.
Step 5: Integrate Red Teaming Into the AI Deployment Lifecycle
A single red team engagement before launch is not a program. A program means red teaming is embedded in the AI development lifecycle: new AI systems are tested before production deployment, existing systems are tested on a defined schedule (quarterly for high-risk systems is the emerging practice standard), and any significant change to a model, its data sources, or its permissions triggers a targeted re-test. NIST AI RMF’s Manage function requires post-deployment monitoring with defined intervention triggers. Red teaming provides the adversarial evidence that feeds those monitoring thresholds.
Companies using AI and automation in security operations contained breaches 108 days faster and saved an average of $2.22 million more than organisations without AI-driven defences. The same defensibility that creates new attack vectors also provides a measurable advantage when used for defence.
Source: IDefence of a Data Breach Report, 2025
We specialise in custom programs and globally recognised certifications at scale.
The Skills Your Team Needs to Run AI Red Team Exercises
AI red teaming requires a combination of skills that most traditional security teams do not yet have. The shortage is real: security teams receive an average of 4,484 alerts per day and spend up to 27% of their time on false positives. Adding AI-specific adversarial testing to this workload without dedicated training and tooling is not viable.
What AI Red Team Members Need to Understand
- LLM architecture and behaviour: How large models process inputs, generate outputs, and where their behavioural boundaries are defined. Without this, adversarial testing is trial and error rather than systematic.
- Prompt engineering and injection techniques: The mechanics of prompt injection, indirect prompt injection, and jailbreaking. These are not intuitive to security professionals trained on code-based vulnerabilities.
- RAG and retrieval architecture: How enterprise retrieval systems work and where they introduce attack surface. This requires an understanding of vector databases, document chunking, and semantic retrieval.
- Agentic AI architecture: How agents plan, use tools, and execute across systems. Agent red teaming requires understanding tool call flows, permission models, and multi-agent interaction patterns.
- MITRE ATLAS and OWASP LLM Top 10: The authoritative attack taxonomies that structure AI red team scope. Using these frameworks ensures systematic coverage rather than ad hoc testing.
DataCouch’s custom AI security training programs build exactly these skills for enterprise security teams: from foundational AI architecture literacy through to hands-on adversarial testing methodology aligned to NIST AI RMF and OWASP standards.
Key Takeaways
- AI red teaming is adversarial testing of AI systems under simulated attack conditions. NIST, MITRE, and OWASP have each published authoritative frameworks that define what to test, how to structure the program, and how to document findings.
- 79% of organisations have no structured AI red teaming program. This gap is where the next wave of enterprise AI security incidents will originate, particularly as agentic AI deployments expand the attack surface.
- The eight attack vectors every red team must cover include prompt injection, jailbreaking, RAG poisoning, model inversion, agent privilege escalation, supply chain attacks, data exfiltration, and behavioural drift. Red teaming requires skills that most traditional security teams do not have: LLM architecture, prompt engineering, retrieval system security, and agentic AI attack patterns. Training is not optional.
- A program means continuous testing embedded in the deployment lifecycle, not a one-time audit. High-risk AI systems require at least quarterly adversarial testing, with re-testing triggered by any significant model or permission change.
- The same AI capability that expands the attack surface also provides measurable defensive advantage. IBM’s data shows AI-augmented security teams save $2.22 million per breach and contain incidents 108 days faster.
Here is the question your security team should be able to answer before any AI system goes into production: if an attacker attempted to manipulate this system through its inputs today, what would they be able to make it do, and how would you detect that it had happened?
If that question does not have a documented answer, the red team exercise has not happened yet.



